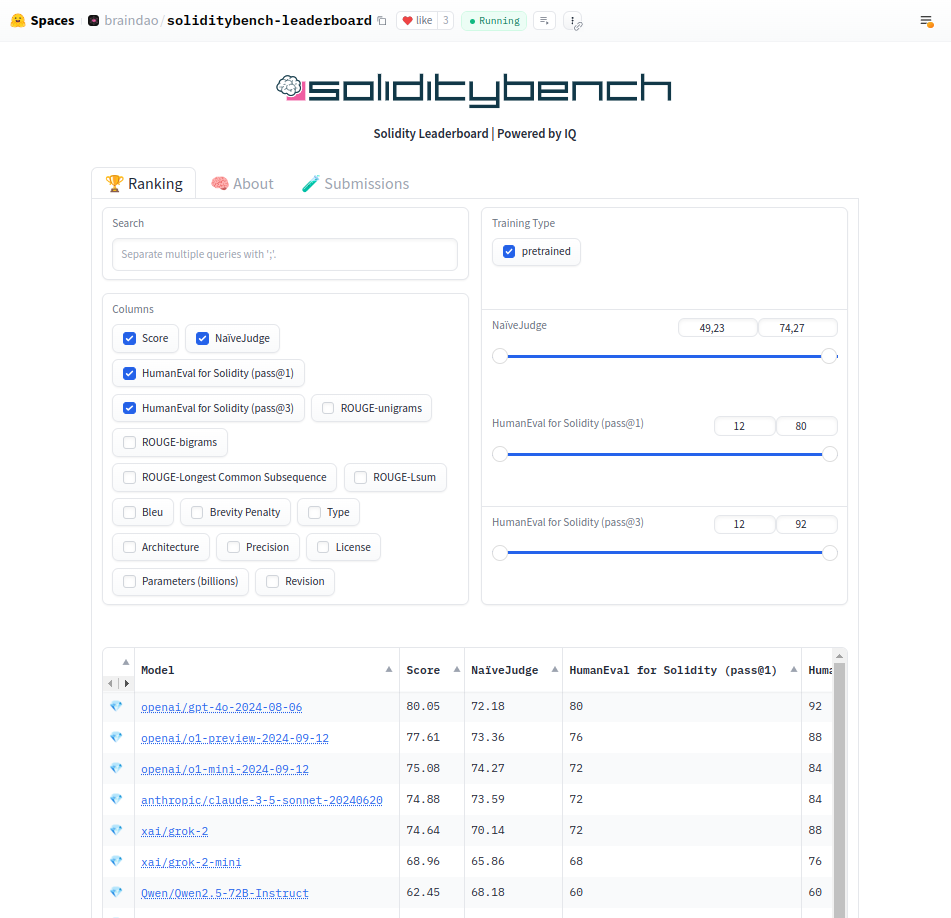
We're excited to announce the launch of SolidityBench by IQ, the first leaderboard for evaluating and ranking the ability of LLM models in Solidity code generation. SolidityBench introduces a new Solidity generation leaderboard now available on Hugging Face, featuring two innovative benchmarks specifically designed for Solidity: NaïveJudge and HumanEval for Solidity. These benchmarks provide a cutting-edge evaluation framework for Solidity code generation with Large Language Models (LLMs).
Advancing IQ Code
BrainDAO developed SolidityBench by IQ as part of building IQ Code, our first suite of AI models designed for generating and auditing smart contract code, which will launch soon. To build the best AI model for smart contracts we first built a ranking system to give ourselves a benchmark. We developed NaïveJudge and HumanEval for Solidity specifically to benchmark our own under-development LLM models tailored for Solidity code generation.
This robust benchmarking toolkit serves two critical purposes:
-
- It drives the continuous refinement and optimization of IQ Code's EVMind LLMs.
-
- It provides a clear comparison between our specialized models and both generalist LLMs and community-created alternatives.
Through SolidityBench, we're not just improving our own technology – we're setting new standards for AI-assisted smart contract development across the entire blockchain ecosystem.
NaïveJudge: A Novel Approach to Smart Contract Evaluation
NaïveJudge represents a significant leap forward in the evaluation of LLM-generated smart contracts by integrating a dataset specifically tailored for this purpose. For this task, LLMs are tasked with implementing smart contracts based on detailed specifications. We created a Hugging Face dataset composed of audited smart contracts from OpenZeppelin with straightforward objectives. These contracts serve as the gold standard for evaluating the correctness and efficiency of the generated code. The prompts for these contracts were generated from the reference code, creating a realistic scenario where the specifications are derived from actual implementations. This approach has been tested across 11 distinct tasks, each designed to challenge the LLM's understanding and implementation of Solidity. This dataset not only aids in testing the functional aspects but also ensures that security and optimization standards are met, mirroring the complexities and nuances of professional smart contract development.
What sets NaïveJudge apart is its evaluation methodology:
-
- The generated code is compared to an audited reference implementation.
-
- The evaluation is performed by state-of-the-art LLMs, specifically OpenAI GPT-4o and Claude 3.5 Sonnet, who act as impartial code reviewers.
-
- The assessment is based on a comprehensive set of criteria, including functional completeness, adherence to Solidity best practices and security standards, and code optimization.
The evaluation criteria for NaïveJudge are rigorous and cover three main areas:
-
- Functional Completeness (0-60 points): This assesses whether the generated code implements all key functionality present in the reference code, handles edge cases, and manages potential errors appropriately.
-
- Solidity Best Practices and Security (0-30 points): This criterion evaluates the use of correct and up-to-date Solidity syntax, adherence to best practices and design patterns, appropriate use of data types and visibility modifiers, and overall code structure and maintainability.
-
- Optimization and Efficiency (0-10 points): This focuses on gas efficiency, unnecessary computations, storage efficiency, and overall performance compared to the expert implementation.
The final score, ranging from 0 to 100, is calculated by summing the points from each criterion, providing a comprehensive assessment of the generated code's quality and effectiveness.
HumanEval for Solidity: Bringing a Classic Benchmark to Smart Contracts
OpenAI's HumanEval is a benchmark dataset designed to assess the code generation capabilities of LLMs. Introduced as part of the research on Codex, HumanEval consists of programming tasks that require not just syntactic correctness but also functional accuracy, challenging models to produce code that not only compiles but also solves the given problem correctly. The evaluation framework for HumanEval involves generating code completions for given prompts, which are then tested for correctness against a set of hidden test cases. This approach aims to evaluate models on their ability to reason about code, understand problem statements, and produce solutions that work, thereby providing a more robust measure of a model's coding proficiency compared to traditional metrics. The dataset and its evaluation methodology have been pivotal in advancing the field, offering insights into the strengths and limitations of AI in code generation tasks.
HumanEval for Solidity is an adaptation of the original HumanEval benchmark, which has been widely used to evaluate code generation capabilities in Python. We've carefully ported a selection of 25 tasks of varying difficulty from the original benchmark to Solidity, published as a HuggingFace dataset. Each task comes with corresponding tests designed for use with Hardhat, a popular Ethereum development environment.
The evaluation process for HumanEval for Solidity is powered by a custom server built on top of Hardhat that is responsible for compiling and testing the Solidity generated code. This setup allows for accurate and efficient testing of generated Solidity code, providing a reliable measure of an AI model's ability to produce fully functional smart contracts.
In the evaluation of Language Models (LLMs) using HumanEval for Solidity, two primary metrics are employed: pass@1 and pass@3. These metrics assign scores ranging from 1 to 100, based on the percentage of tasks the model successfully completes. The pass@1 score assesses the model's precision and efficiency by measuring its success on the first try. Conversely, pass@3 offers up to three attempts at solving each task, providing insights into the model's capability to solve problems over multiple tries.

HumanEval for Solidity Server running on a HuggingFace Space
Advancing the Field of LLM-Generated Smart Contracts
SolidityBench represents a significant step forward in the evaluation of LLM-generated Solidity code. By providing these two complementary benchmarks, we aim to:
-
- Encourage the development of more sophisticated and reliable AI models for smart contract generation.
-
- Provide developers and researchers with valuable insights into the current capabilities and limitations of AI in Solidity development.
-
- Foster a community-driven approach to improving smart contract quality and security.
We invite developers, researchers, and AI enthusiasts to explore and contribute to SolidityBench. Your involvement can significantly impact the future of AI-assisted smart contract development. Join us in pushing the boundaries of decentralized applications and blockchain technology.
Visit the SolidityBench leaderboard on Hugging Face to learn more and start benchmarking your Solidity generation models today!
About IQ
The IQ token is a cryptocurrency dedicated to building a more intelligent future through artificial intelligence and blockchain technology. The IQ token powers a knowledge ecosystem including applications such as IQ.wiki, the world's largest cryptocurrency and blockchain encyclopedia, IQ GPT, the AI agent for cryptocurrency and blockchain, IQ.social, an AI-powered social forum governed by IQ holders that summarizes crypto-related news, and IQ Code, an upcoming AI product created to assist people in coding Solidity and Vyper sets. The token is governed by BrainDAO which also includes BrainDAO's treasury of digital assets.
Twitter | IQ.wiki | IQ Dashboard | IQ Code | IQ GPT | IQ.social | Reddit | Discord | Telegram | Governance | Github



