0% read
Chengxu Zhuang
Chengxu Zhuang
Chengxu Zhuang은 Meta의 인공지능 연구 과학자입니다. 그는 자연어 처리, 컴퓨터 비전, 계산 신경 과학 분야에서 활동하며 OpenAI의 ChatGPT와 현재 Meta의 초지능 팀에 기여한 것으로 알려져 있습니다. [1] [2]
교육
Zhuang은 2011년부터 2016년까지 칭화대학교에 다녔으며, 그곳에서 전자 공학 학사 학위와 수학 학사 학위를 받았습니다. 이후 2016년부터 2022년까지 스탠포드 대학교에서 박사 과정을 밟아 Daniel Yamins의 지도하에 심리학 박사 학위를 취득했습니다. 박사 학위 후 Zhuang은 2022년부터 2024년까지 매사추세츠 공과대학교(MIT)에서 ICoN 박사후 연구원으로 Ev Fedorenko 및 Jacob Andreas와 함께 연구했습니다. [1] [5]
경력
Zhuang은 MIT의 EvLab에서 박사후 경력을 시작하여 언어와 뇌 과학의 교차점에 집중했습니다. 이후 OpenAI에 합류하여 ChatGPT 고급 음성 모드 개발에 기여했습니다. 2025년에는 Meta의 AI 연구 과학자 역할로 전환했습니다. 그는 최근 결성된 회사의 "초지능" 팀의 일원이며, 이 팀은 인공 일반 지능 연구를 발전시키기 위해 구성된 그룹입니다. 이 팀에는 OpenAI 및 Google의 DeepMind와 같은 주요 AI 조직의 수많은 연구원과 엔지니어가 포함되어 있습니다.
스탠포드에 있는 동안 Zhuang은 행동 및 사회 과학을 위한 통계 방법, 실험 방법, 신경 과학을 위한 대규모 신경망 모델, 행동 및 신경 데이터를 위한 고차원 방법 등 여러 과정에서 조교로 활동했습니다. [1] [3] [4] [5] [7]
연구 및 출판물
Zhuang의 연구 관심사는 자연어 처리, 언어 습득, 컴퓨터 비전, 계산 신경 과학 및 딥 러닝을 포함합니다. 그의 연구는 종종 생물학적 지능과 인공 지능 모델 간의 연결을 탐구합니다.
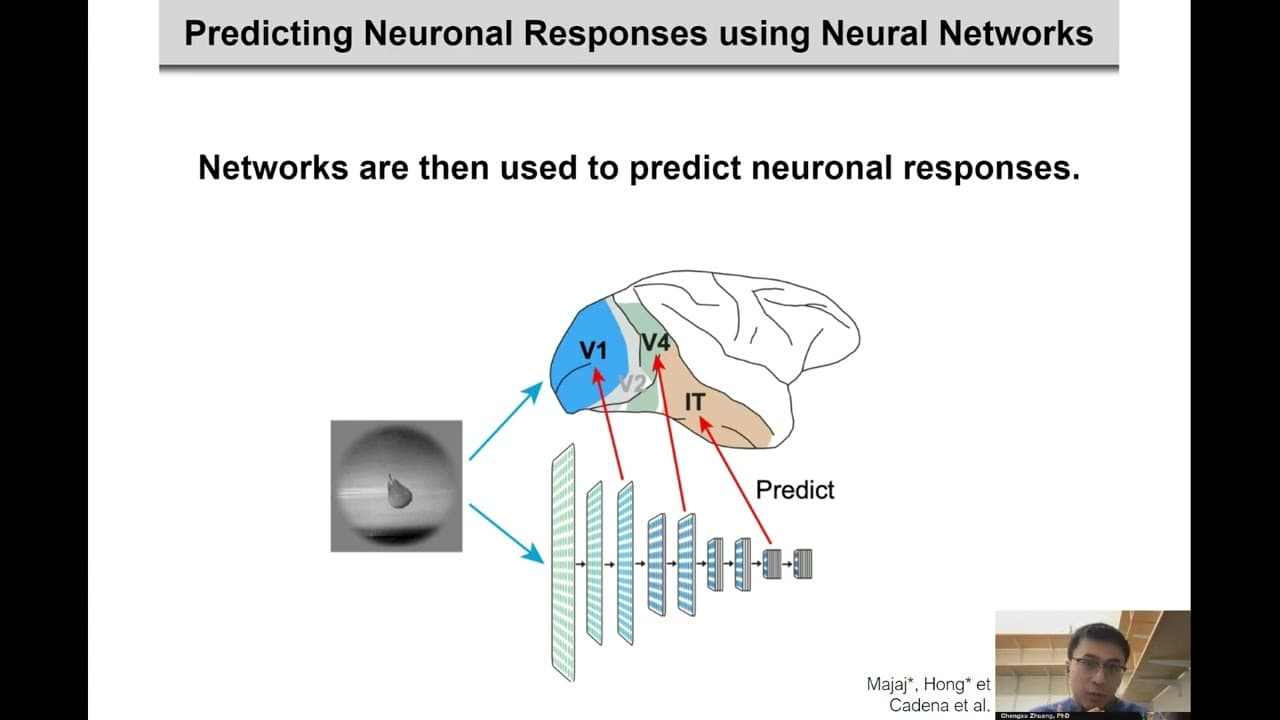
그는 주요 AI 및 신경 과학 컨퍼런스에서 발표된 수많은 논문의 공동 저자입니다. 그의 출판물은 비디오에서 얻는 비지도 학습, 복부 시각 스트림을 위한 신경망 모델 개발, 언어 모델링을 개선하기 위한 시각적 접지 사용과 같은 주제를 다룹니다. [1] [6]
주요 출판물
- "시각적 접지는 낮은 데이터 환경에서 단어 의미를 배우는 데 도움이 됩니다" (2024): Evelina Fedorenko 및 Jacob Andreas와 공동 저술한 이 논문은 북미 전산 언어학 협회(NAACL) 컨퍼런스에서 발표되었으며, 여기서 최우수 논문상을 받았습니다.
- "어휘 수준의 대조적인 시각적 접지는 언어 모델링을 개선합니다" (2024): 이 연구는 전산 언어학 협회(ACL)의 연구 결과에 게재되었습니다.
- "비지도 학습 알고리즘은 인간의 실시간 및 평생 학습을 얼마나 잘 모델링합니까?" (2022): NeurIPS 데이터 세트 및 벤치마크 트랙에서 발표된 이 논문은 AI의 비지도 학습과 인간 학습 과정 간의 유사성을 조사합니다.
- "복부 시각 스트림의 비지도 신경망 모델" (2021): 미국 국립 과학원 회보(PNAS)에 게재된 이 연구는 뇌의 시각 처리 시스템을 시뮬레이션하기 위해 비지도 모델을 사용하는 것을 탐구합니다.
- "시각적 임베딩의 비지도 학습을 위한 로컬 집계" (2019): 컴퓨터 비전 국제 컨퍼런스(ICCV)에서 발표된 이 논문은 최우수 논문상 후보에 올랐습니다.
- "설치류 수염-삼차 신경계에 대한 목표 지향적 신경망 모델을 향하여" (2017): 설치류의 감각 시스템에서 영감을 얻은 신경망 모델을 만드는 것을 목표로 한 NIPS 컨퍼런스에서 발표된 초기 연구입니다.
잘못된 내용이 있나요?

평균 평점
1개의 평가를 기반으로
경험은 어땠나요?
빠른 평가를 해서 우리에게 알려주세요!
편집자
August 26, 2025. 16:49 UTC
편집 요약:
docs: Embed YouTube videos related to research and publications in the article.