0% read
마지막 업데이트:
Jason Wei
Jason Wei는 chain-of-thought 프롬프팅 개발을 포함하여 대규모 언어 모델에 대한 기여로 알려진 미국의 인공 지능 연구원입니다. 현재 Meta Superintelligence Labs의 연구원으로, 이전에는 OpenAI와 Google Brain에서 근무했습니다. [1] [2]
경력
Wei는 Google Brain에서 연구 과학자로 경력을 시작했으며, 그의 연구는 대규모 언어 모델(LLM)의 기능 향상에 중점을 두었습니다. Google에서 근무하는 동안 그는 해당 분야의 여러 주요 기술을 대중화하는 데 중요한 역할을 했습니다. chain-of-thought 프롬프팅에 대한 그의 연구는 LLM이 인간과 유사한 사고 과정을 모방하여 중간 단계를 생성함으로써 복잡한 추론 작업을 보다 효과적으로 수행할 수 있음을 보여주었습니다. 그는 또한 사용자의 지시를 더 잘 따르도록 언어 모델을 미세 조정하는 방법인 instruction tuning 개발에 기여했으며, 모델 규모가 커짐에 따라 나타나는 예상치 못한 기능인 LLM의 창발적 능력에 대한 연구를 수행했습니다. [1] [3]
2023년 2월, Wei는 Google을 떠나 OpenAI의 ChatGPT 팀에 합류했다고 발표했습니다. [4] OpenAI에서 그는 고급 AI 모델에 대한 연구를 계속했으며, 더 복잡한 문제를 처리하기 위해 답변을 제공하기 전에 더 많은 시간을 "생각"하도록 설계된 모델 시리즈인 OpenAI o1 모델의 공동 제작자였습니다. 그는 또한 "심층 연구"로 알려진 프로젝트를 진행했습니다. [1] [2] OpenAI에 있는 동안 Wei는 모델의 성능을 개선하기 위해 피드백을 사용하는 훈련 방법인 강화 학습(RL)의 강력한 지지자가 되었습니다. 그는 자신을 "RL 광신도"라고 묘사했으며, 그 핵심 개념이 자신의 개인 철학에 어떻게 영향을 미쳤는지 언급하면서 "선생님을 이기려면 자신만의 길을 걷고 환경에서 위험과 보상을 감수해야 합니다."라고 말했습니다. [3] [5]
2025년 7월, Wei는 그의 친한 동료인 Hyung Won Chung과 함께 OpenAI를 떠나 Meta의 새로 설립된 Superintelligence Labs에 합류할 것이라고 보도되었습니다. 추론 및 강화 학습에 대한 Wei의 전문 지식은 Meta의 목표에 중요한 자산으로 여겨졌습니다. [1] [2] [6]
주요 작품
Wei는 인공 지능 분야 내에서 여러 영향력 있는 연구 분야 및 모델에 기여했습니다. 그의 연구는 주로 대규모 언어 모델의 추론 및 일반화 기능 향상에 중점을 두었습니다.
Chain-of-Thought 프롬프팅
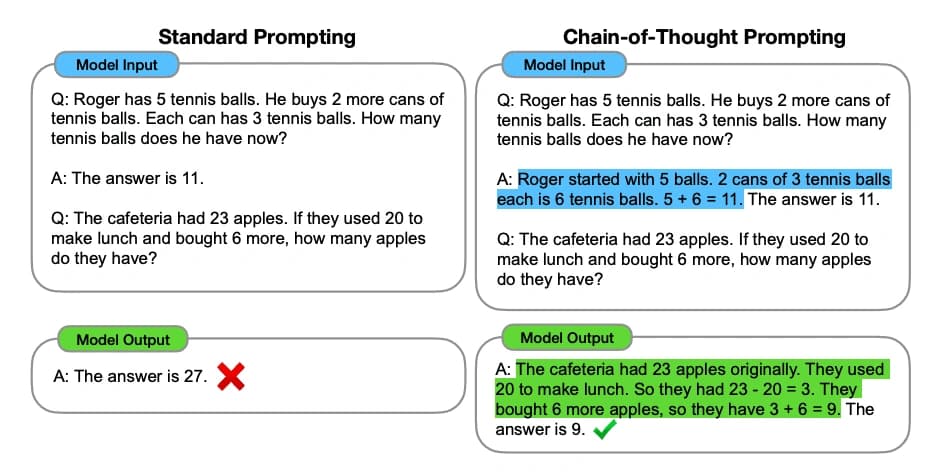
Google에 있는 동안 Wei는 chain-of-thought(CoT) 프롬프팅으로 이어진 연구의 핵심 인물이었습니다. 이 기술은 언어 모델이 최종 답변을 제공하기 전에 다단계 문제를 중간 추론 단계로 분해하도록 유도합니다. "사고 과정"을 외부화함으로써 모델은 산술, 상식 및 상징적 추론과 같은 영역에서 복잡한 작업에 대한 보다 정확하고 신뢰할 수 있는 솔루션에 도달할 수 있습니다. 2022년 논문 "Chain-of-Thought Prompting Elicits Reasoning in Language Models"에 발표된 이 연구는 방법론을 대중화하고 LLM 추론에 대한 후속 연구에 큰 영향을 미쳤습니다. [1] [3]
Instruction Tuning 및 창발적 능력
Wei는 또한 instruction tuning, 특히 Google의 FLAN(Finetuned Language Net) 모델에 대한 연구에 기여했습니다. Instruction tuning은 지침으로 형식이 지정된 데이터 세트 모음에서 사전 훈련된 언어 모델을 미세 조정하는 것을 포함합니다. 이 프로세스는 모델이 제로샷 설정에서 광범위한 보이지 않는 작업을 수행하는 능력을 향상시켜 보다 범용적이고 사용자 의도에 부합하도록 만듭니다. 그의 연구는 "Finetuned Language Models are Zero-Shot Learners"(2021) 및 "Scaling Instruction-Finetuned Language Models"(2022)와 같은 논문에 자세히 설명되어 있습니다. 동시에 그는 "Emergent Abilities of Large Language Models"(2022) 논문의 공동 저자이기도 하며, LLM의 특정 기능이 원활하게 개선되는 것이 아니라 모델 크기 및 훈련 데이터의 특정 규모에서 예측할 수 없이 나타나는 방식을 특징지었습니다. [1]
OpenAI o1 모델
OpenAI에서 Wei는 2024년 9월에 미리보기 릴리스로 소개된 o1 모델의 공동 제작자였습니다. o1 모델 시리즈는 응답을 생성하기 전에 더 많은 계산 노력 또는 "생각 시간"을 할당하여 이전 모델의 추론 제한 사항을 개선하도록 설계되었습니다. 이 접근 방식을 통해 모델은 과학, 수학 및 코딩과 같은 분야에서 복잡한 작업을 보다 정확하게 추론할 수 있습니다. Wei는 이 모델이 단순한 chain-of-thought 프롬프팅을 넘어 보다 정교한 추론 프로세스로 이동하는 AI 분야의 중요한 업데이트라고 설명했습니다. [7] [2]
잘못된 내용이 있나요?

평균 평점
아직 평가가 없습니다
경험은 어땠나요?
빠른 평가를 해서 우리에게 알려주세요!
편집자
August 15, 2025. 18:05 UTC
편집 요약:
Published Jason Wei's wiki