0% read
Kimi (Language Model)
Kimi (Language Model)
Kimi 是由总部位于北京的初创公司 Moonshot AI 开发的一系列大型语言模型 (LLM)。这些模型以其大型上下文窗口而闻名,并且在后来的版本中,以其开放权重架构和智能代理能力而闻名,这使它们能够执行复杂的、多步骤的任务。
比较加密资产
选择一个资产,与 Kimi (Language Model) 比较价格和其他数据。
生态系统图
探索 Kimi (Language Model) 关联的维基及其在图上的关系。
Kimi 聊天机器人 (2023)
最初的 Kimi 聊天机器人由 Moonshot AI 于 2023 年 10 月推出。当时,它与众不同的一个关键特征是其大型上下文窗口,能够在单个提示中处理多达 200,000 个汉字。这种能力使其成为中国竞争激烈的 AI 市场中的有力竞争者,专注于处理长文档和复杂的对话。该模型的长上下文能力是 Moonshot AI 战略的核心组成部分,这促使该公司在 2024 年初达到了 25 亿美元的估值。 [6] [7]
Kimi K2 (2025)
概述
Kimi K2 于 2025 年 7 月 11 日由 Moonshot AI 推出,该公司成立于 2023 年 3 月。它是一个开放权重的专家混合 (MoE) 模型,其设计重点是智能代理。该版本的发布引起了 AI 研究界的广泛关注,一些人将其影响与今年早些时候 DeepSeek 模型的发布相提并论。 [1] 该模型以其在编码和推理基准测试中的性能而闻名,在非思维评估中,它与许多当代开源和专有模型(包括 Anthropic 的 Claude 等西方竞争对手)相匹配或超过。 [1] 机器学习研究员 Nathan Lambert 在其发布后将其描述为“世界上最好的新开放模型”。 [1]
Kimi K2 的出现是在美国与中国 AI 竞争的更广泛背景下看待的,Moonshot AI 定位为 OpenAI 和 Anthropic 等西方 AI 实验室的重要中国竞争对手。据报道,这家初创公司得到了包括中国科技巨头阿里巴巴在内的投资者的支持。 [1]
Kimi K2 背后的核心设计理念是“智能代理”,它优先考虑模型作为自主代理的能力。它并非简单地响应提示,而是被设计为理解用户的目标,选择合适的工具(例如 Web 浏览器、代码解释器或 API),并执行一系列操作以实现该目标。这种方法旨在超越简单的基于聊天的交互,转向更复杂的问题解决。 [2]
Moonshot AI 发布了该模型的两个主要变体,以满足不同的用例。Kimi-K2-Base 是基础模型,适用于需要完全控制进行自定义微调的研究人员和开发人员。Kimi-K2-Instruct 是一个经过后期训练的版本,针对通用聊天和即用型智能代理应用程序进行了优化。模型权重和相关代码均在修改后的 MIT 许可证下发布,以促进开放研究和开发。 [3]
技术
架构
Kimi K2 构建在专家混合 (MoE) 架构之上,该架构允许非常多的总参数,同时保持每个推理的激活参数在计算上易于管理。这种设计提高了效率和可扩展性。该模型共有 1 万亿个参数,每个令牌激活 320 亿个参数。 [4]
关键架构规范包括:
- 总参数:1 万亿
- 激活参数:320 亿
- 模型层:61(包括 1 个密集层)
- 注意力头:64
- 专家总数:384(每个令牌选择 8 个)
- 上下文长度:128,000 个令牌
- 词汇量:160,000
- 激活函数:SwiGLU
- 注意力机制:多层注意力 (MLA)
这些规范在项目的官方技术文档中详细说明。 [3]
训练和优化
Kimi K2 在包含 15.5 万亿个令牌的数据集上进行了预训练。其开发过程中的一项重大技术创新是创建了 MuonClip 优化器。开发此优化器是为了解决训练不稳定性,这是缩放大型模型时常见的挑战,特别是“注意力 logits 爆炸”的问题。 [2]
MuonClip 优化器通过引入一种称为“qk-clip”的技术来构建在 Muon 优化器之上。此方法通过在每次更新后直接重新缩放查询 (q) 和键 (k) 投影的权重矩阵来稳定训练。通过控制注意力 logits 在其源头的规模,MuonClip 有效地防止了损失峰值,从而实现了整个 15.5T 令牌数据集的稳定预训练过程。 [4]
智能代理能力开发
该模型的高级智能代理功能是通过一个多阶段的后期训练过程开发的,该过程侧重于工具使用和强化学习。
大规模智能代理数据合成
为了教会模型如何有效地使用工具,开发团队创建了一个大规模的数据合成管道。该系统受到 ACEBench 框架的启发,模拟了涉及数百个领域和数千个工具的复杂、真实世界的场景。在这些模拟中,AI 代理与模拟环境和用户代理交互,以生成逼真的、多轮的工具使用数据。然后,基于 LLM 的判断器根据预定义的规则评估这些交互,以筛选出高质量的示例,这些示例用于训练。 [2]
通用强化学习
Kimi K2 的训练包含一个通用强化学习 (RL) 系统,该系统旨在处理具有可验证奖励(例如,解决数学问题)和不可验证奖励(例如,编写高质量报告)的任务。对于不可验证的任务,该系统采用自我判断机制,其中模型充当自己的评论员,提供可扩展的、基于规则的反馈。使用来自具有可验证奖励的任务的策略内推出不断改进和校准此评论员,从而确保其评估准确性保持较高水平。此过程允许模型从更广泛的交互中学习,使其摆脱了人工注释数据的限制。 [4]
性能和基准测试
根据其开发人员和独立分析,Kimi K2 在开源、非思维模型中表现出最先进的性能,并且与西方实验室的领先专有模型具有很强的竞争力。 [1] [8] 该模型在智能代理任务、编码和数学方面尤其出色。
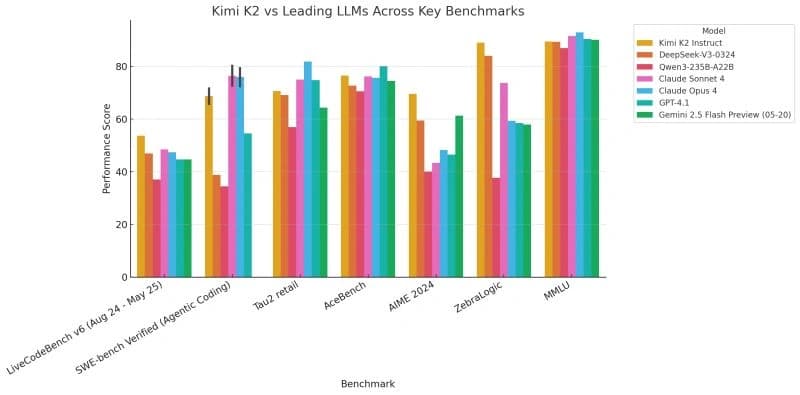
在智能代理编码评估中,Kimi K2 在 SWE-bench Verified(单次尝试)中获得了 65.8% 的分数,超过了 GPT-4.1 (54.6%),并且与 Claude 4 Opus (72.5%) 的表现相当。它还在 SWE-bench Multilingual 上获得了 47.3% 的分数。对于通用工具使用,其在 AceBench(英语)上的 76.5% 的分数与 Claude 4 Opus (75.6%) 和 GPT-4.1 (80.1%) 具有竞争力。该模型在编码基准测试中表现出强大的性能,在 LiveCodeBench v6 上实现了 53.7% 的 Pass@1 率,高于 Claude 4 Opus (47.4%) 和 GPT-4.1 (44.7%)。在 OJBench 上,其 27.1% 的分数也超过了其专有对应产品。在数学和 STEM 方面,Kimi K2 在 AIME 2025 基准测试中获得了 49.5% 的分数,大大优于 Claude 4 Opus (33.9%) 和 GPT-4.1 (37.0%)。在 GPQA-Diamond 基准测试中,其 75.1% 的分数与 Claude 4 Opus (74.9%) 持平,并且领先于 GPT-4.1 (66.3%)。这些结果在模型的技术报告中详细说明,将 Kimi K2 定位为一种功能强大的模型,尤其适用于与软件工程和自主问题解决相关的任务。 [2] [4]
用例和应用程序
Kimi K2 旨在自主使用工具来完成复杂的用户请求。它可以解释高级任务描述,确定必要的步骤,并使用集成的工具(如代码解释器或 Web 浏览器)执行这些步骤,而无需预先编写的工作流程。
Moonshot AI 演示的一个突出示例是薪资数据分析任务。给定一个数据集和一个高级提示,Kimi K2 使用 IPython 工具执行了一个 16 步的过程。这包括加载和筛选数据、对远程工作比率进行分类、执行统计分析(如双向方差分析和 t 检验)、生成多个可视化效果(例如,小提琴图、箱线图、条形图)以及总结结果。最终输出是一个完整的、交互式的 HTML 网页,其中展示了分析和一个用于个性化推荐的集成模拟器。 [2]
其他演示的用例包括:
- Web 开发:通过命令行工具交互从头开始编写基于 Web 的 3D 版 Minecraft。
- 旅行计划:通过进行 17 次无缝工具调用来集成搜索、日历、Gmail、航班预订和餐厅预订服务,从而制定详细的旅行行程。
- 研究协助:通过一系列 Web 搜索、页面浏览和代码编辑操作,生成一个可视化 Stanford NLP Genealogy 的交互式网站。
这些示例突出了该模型协调多个工具以实现复杂、多方面目标的能力。 [2]
可用性
可以通过以下几个渠道访问 Kimi K2:
- Web 和移动设备:可以通过其官方网站和移动应用程序上的 Kimi 聊天界面免费公开使用 Kimi K2 模型。 [5]
- API 访问:开发人员可以通过 Kimi 平台将 Kimi K2 集成到他们的应用程序中,该平台提供与 OpenAI 和 Anthropic 标准兼容的 API,以方便采用。
- 自托管:
Kimi-K2-Base和Kimi-K2-Instruct的开放权重模型检查点可在 Hugging Face 上获得。可以使用 vLLM、SGLang、KTransformers 和 TensorRT-LLM 等推理引擎在本地或云中部署它们。
该模型及其源代码在修改后的 MIT 许可证下发布。 [3]
局限性
开发人员已经确定了 Kimi K2 初始版本中的几个局限性。当面临困难的推理任务或定义不明确的工具时,该模型可能会生成过多的令牌,这有时会导致输出不完整。在某些情况下,启用工具使用会降低其他任务的性能。此外,对于复杂的软件开发项目,该模型在智能代理框架内的表现优于简单的单次提示。在其发布时不支持视觉功能,但计划在未来的更新中解决这些局限性。 [2]
发现错误了吗?

平均评级
暂无评分
您的体验如何?
给这个维基一个快速评分让我们知道!
编辑者
2025年8月1日。15:10 UTC
编辑摘要:
Updated wiki title to "Kimi (Language Model)"