Hone
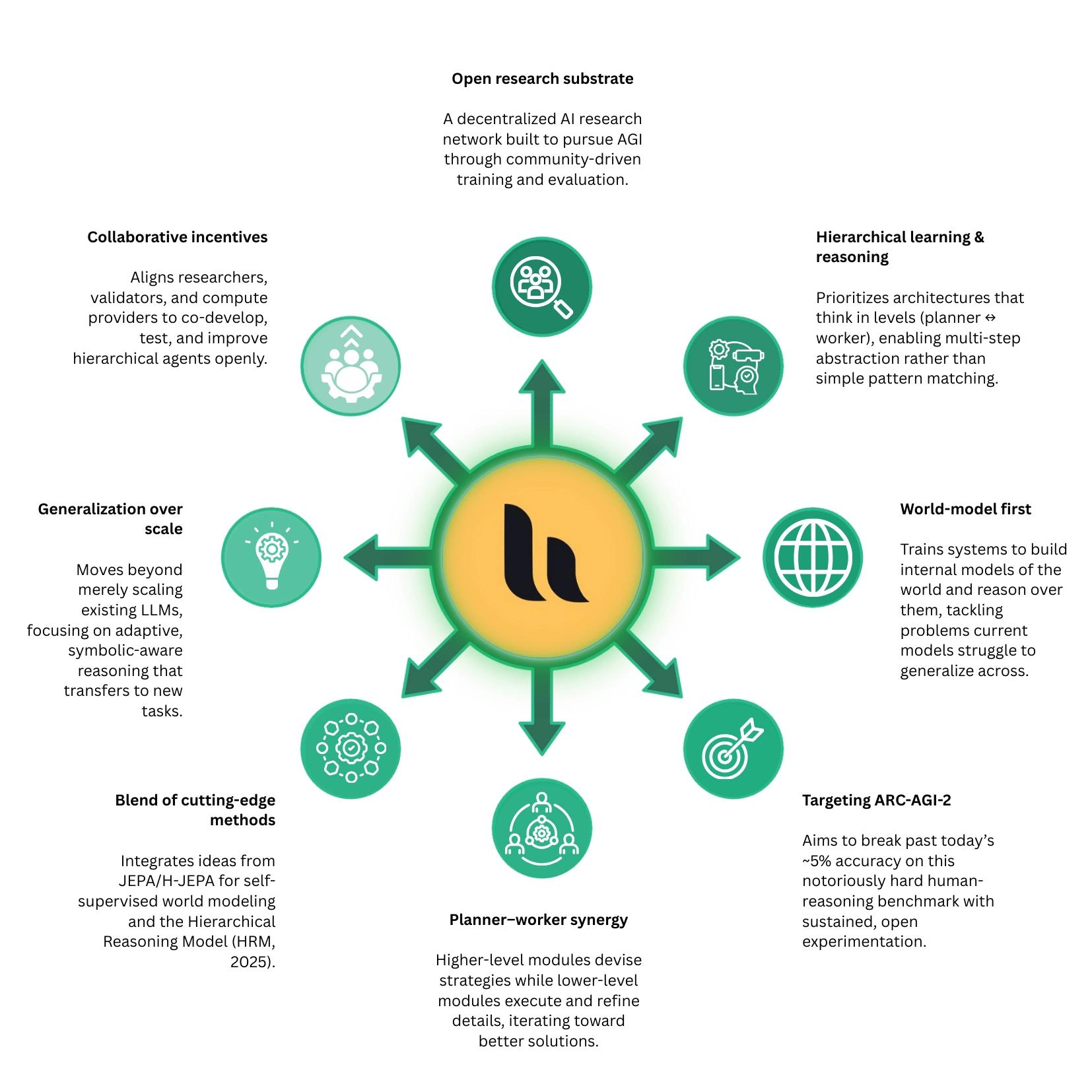
Hone (formerly OpenKaito and known on-chain as Subnet-5) is a decentralized artificial intelligence subnet on the Bittensor network that focuses on training, evaluating, and serving hierarchical learning and reasoning systems through distributed participation. The project emphasizes world-model learning and iterative, planner–executor reasoning loops, with performance-based evaluation by independent validators and an explicit focus on improving abstract problem-solving benchmarks. Hone operates as an open, incentive-aligned research and infrastructure effort rather than a single static model release. [1]
Overview
Hone (formerly OpenKaito) is a decentralized AI and search initiative built on the Bittensor network, focused on creating an open, continuously improving layer for information access and reasoning. It combines decentralized search infrastructure with ongoing model training to support transparent, composable, and scalable information retrieval.
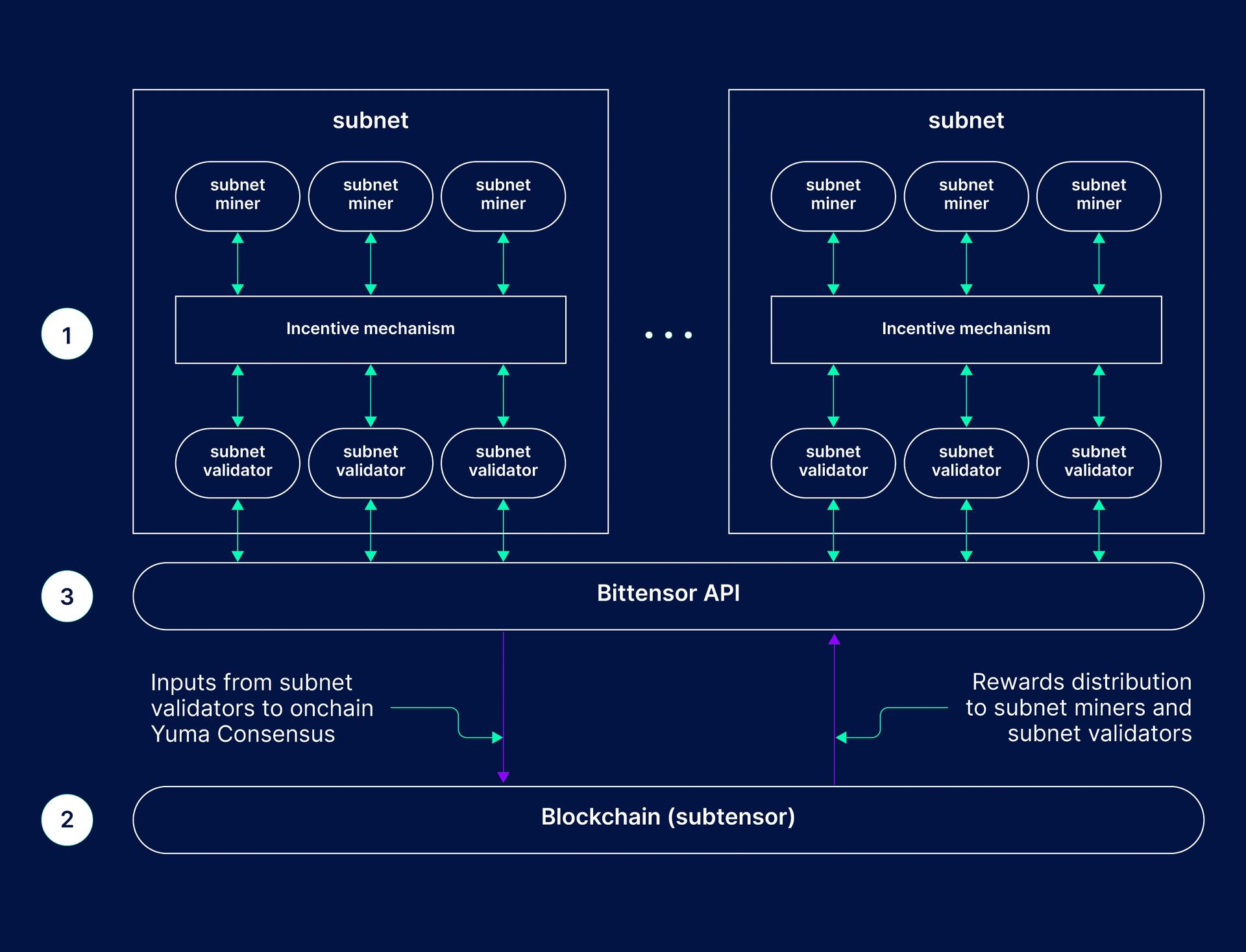
As Hone (Subnet-5), the project centers on training general-purpose AI models using hierarchical learning and reasoning architectures. Instead of relying on conventional large-language model scaling, it develops systems in which higher-level planning components and lower-level execution components interact iteratively, enabling structured, multi-step problem-solving rather than one-pass outputs. The subnet functions as a distributed training and evaluation system. Participants contribute models and training processes, while independent validators assess performance using evolving datasets and benchmarks. Incentives are tied to measurable results, creating a continuous cycle of competition and improvement that refines model quality over time without centralized control.
A core objective is to improve performance on difficult reasoning benchmarks, such as ARC-AGI-2, which measure abstract problem-solving ability. To achieve this, the system incorporates approaches such as joint embedding predictive architectures and hierarchical reasoning models, enabling models to build internal representations, plan solutions, and adapt to new tasks. The output is not a single fixed model but an evolving, decentralized AI system. Over time, these models are intended to be accessible through network APIs, supporting applications such as semantic search, complex analysis, and general reasoning, while remaining open, continuously updated, and collectively developed. [1] [3]
History
Hone (formerly OpenKaito) originated as Subnet-5 within the Bittensor ecosystem, initially focused on decentralized search and text embedding models. On May 1, 2025, ownership of the subnet was transferred from its original creator to Latent Holdings, marking a shift in direction and scope. Following the transfer, a new development strategy was introduced in collaboration with Manifold Labs. Rather than continuing to focus primarily on search and embeddings, the subnet was repositioned toward building general-purpose reasoning systems using hierarchical AI architectures. This transition reflected a broader move from information retrieval toward more advanced AI capabilities.
On August 7, 2025, Subnet-5 was formally relaunched as Hone, reflecting its updated technical focus and research direction. From that point onward, the project centered on decentralized training of reasoning models, integrating approaches such as world-model learning and iterative reasoning within the Bittensor framework. The development of Hone is led jointly by Manifold Labs and Latent Holdings. Manifold contributes experience in building and operating Bittensor subnets and related infrastructure, while Latent provides strategic direction focused on open-source AI development. Together, the two organizations established Hone as a decentralized research and infrastructure effort aimed at advancing general-purpose AI systems. Since its relaunch, Hone has evolved from a specialized, embedding-focused subnet into a broader platform for distributed training and evaluation of reasoning models. [1] [2]
Architecture
World-Model Learning
The World-Model Learning module focuses on self-supervised predictive learning, drawing from joint embedding predictive architectures (JEPA) and hierarchical extensions. The core objective is to train the model to understand data structure by predicting missing or masked information, rather than relying on labeled supervision. In practice, the model is exposed to partial inputs—such as incomplete patterns, sequences, or structured data—and must infer the latent representation of what is missing. This encourages the system to learn relationships between variables, causal structure, and context, forming a compressed internal representation often described as a “world model.”
A key aspect is hierarchical representation learning. Instead of learning a single flat embedding space, the model develops multiple levels of abstraction simultaneously—for example, low-level features (patterns, tokens) and higher-level concepts (rules, relationships). These layers allow the system to generalize more effectively across domains, since it can reuse abstract knowledge rather than memorizing surface-level correlations. This module serves as the foundation of the system: it equips the model with broad, transferable knowledge and contextual understanding, which is necessary for downstream reasoning tasks. Without this step, reasoning modules tend to operate on shallow or brittle representations. [1]
Hierarchical Reasoning
The Hierarchical Reasoning module builds on top of the learned representations and introduces an explicit multi-step reasoning process inspired by hierarchical reasoning architectures. Instead of generating outputs in a single forward pass, the model is structured into two interacting components that operate over multiple iterations. The high-level component functions as a planner. It generates an abstract strategy, hypothesis, or partial solution based on the input and the current state of reasoning. The low-level component acts as an executor, taking that plan and working through concrete steps—such as filling in details, testing transformations, or constructing intermediate outputs.
These components interact in a recurrent loop. After each iteration, the executor's output is fed back into the planner, which evaluates progress and decides whether to refine the strategy, adjust assumptions, or terminate the process. This creates a dynamic reasoning cycle where the model incrementally improves its solution. This design allows the system to handle tasks that require decomposition, backtracking, and iterative refinement—capabilities that are limited in standard transformer-based models. It also enables reasoning across different time scales: slower, higher-level planning guides faster, detail-oriented execution. The hierarchical structure also improves computational efficiency. Instead of scaling a single large model to handle all reasoning in one pass, the system reuses smaller components across multiple iterations, achieving deeper reasoning without a proportional increase in model size. [1]