0% read
最后更新:
Hone
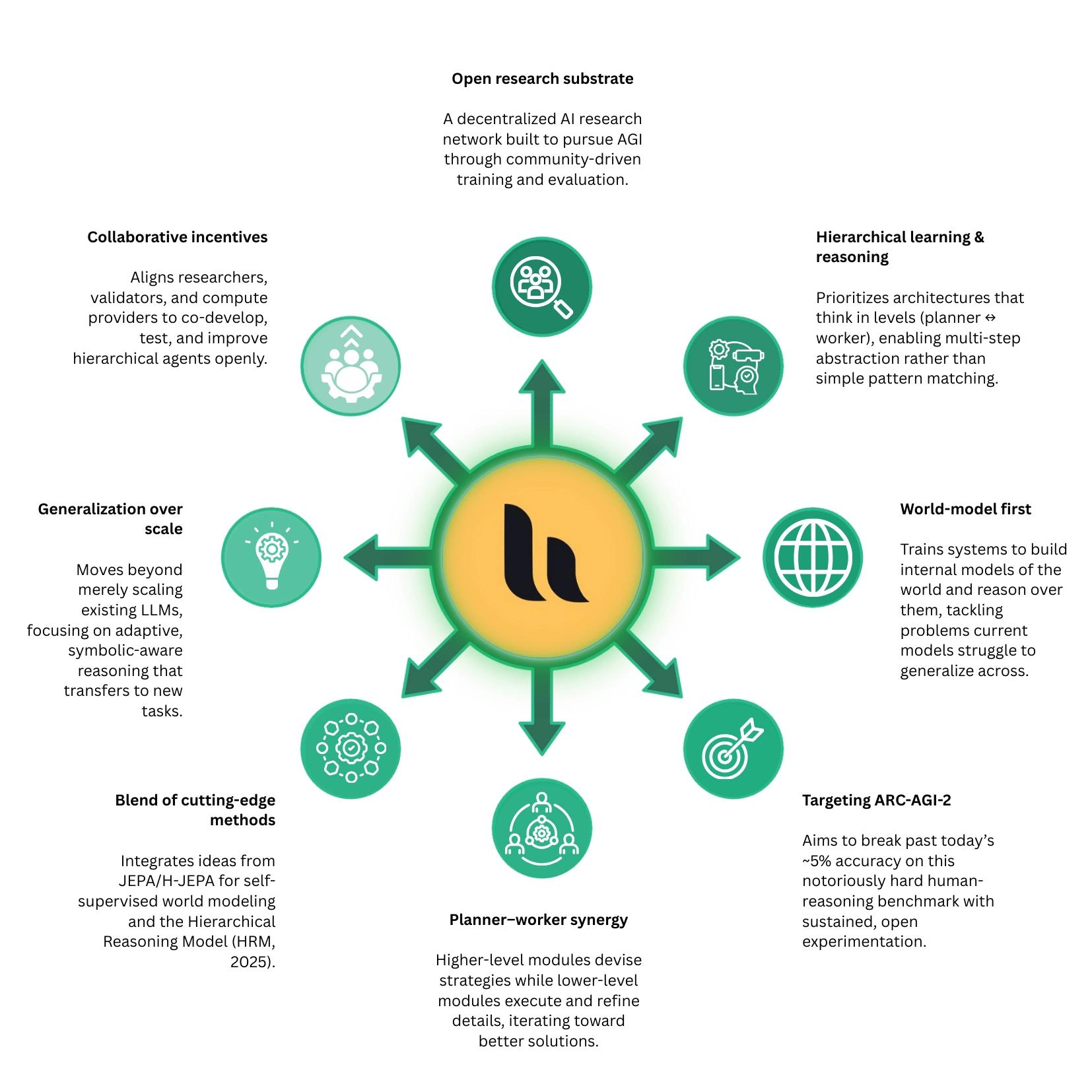
Hone(前身为 OpenKaito,在链上被称为 Subnet-5)是 Bittensor 网络上的一个去中心化人工智能子网,专注于通过分布式参与来训练、评估和提供分层学习与推理系统。该项目强调世界模型学习和迭代式的“规划者-执行者”推理循环,由独立验证者进行基于性能的评估,并明确专注于改进抽象问题解决基准。Hone 作为一个开放的、激励一致的研究和基础设施项目运行,而非单一的静态模型发布。[1]
概述
Hone(前身为 OpenKaito)是建立在 Bittensor 网络上的去中心化 AI 和搜索计划,致力于为信息访问和推理创建一个开放、持续改进的层。它将去中心化搜索基础设施与持续的模型训练相结合,以支持透明、可组合且可扩展的信息检索。
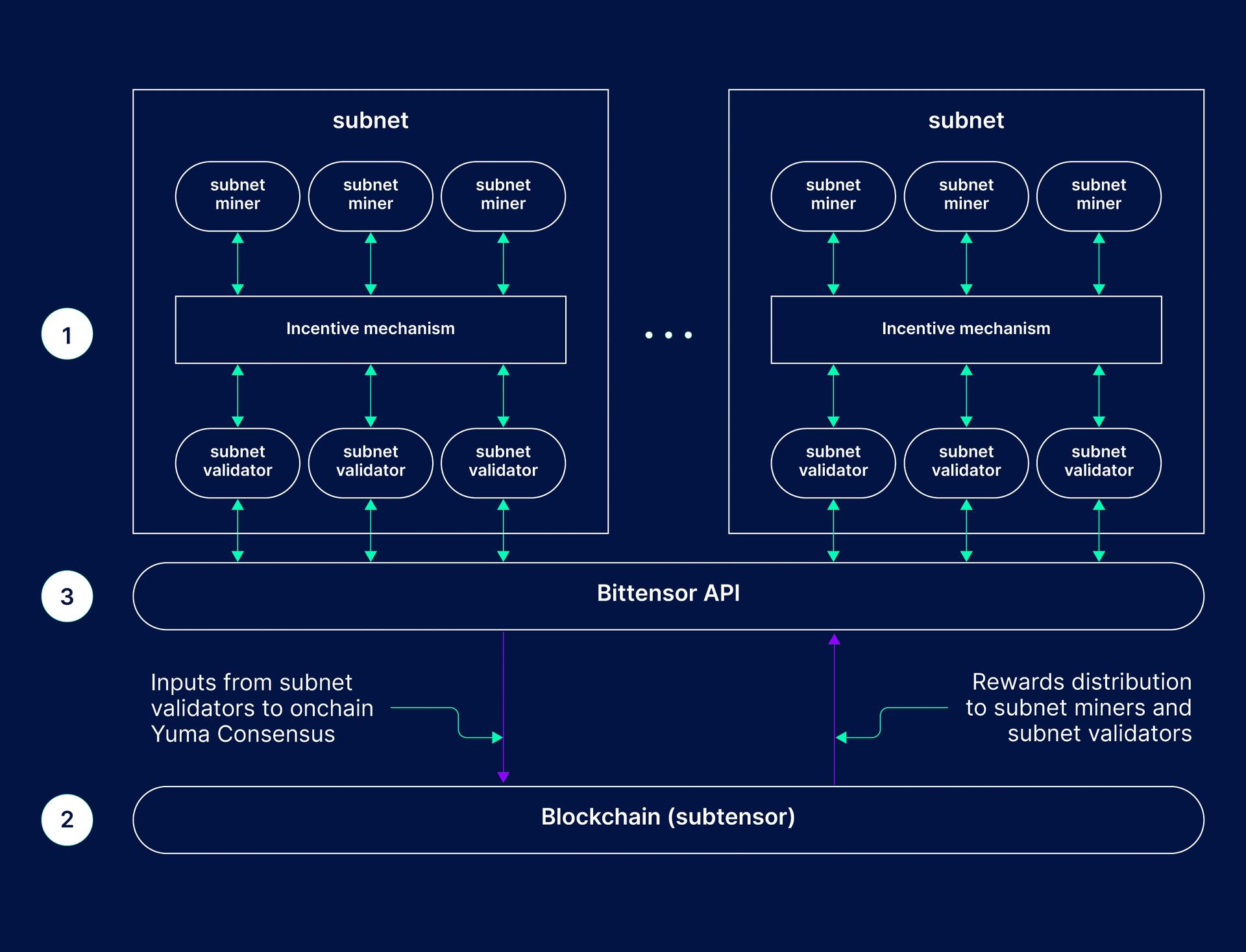
作为 Hone (Subnet-5),该项目的核心是使用分层学习和推理架构训练通用 AI 模型。它不依赖于传统的超大规模语言模型扩展,而是开发一种系统,其中高层规划组件和底层执行组件进行迭代交互,从而实现结构化的多步问题解决,而非一次性输出。该子网作为一个分布式训练和评估系统运行。参与者贡献模型和训练过程,而独立的验证者则使用不断演进的数据集和基准来评估性能。激励机制与可衡量的结果挂钩,创造了一个持续竞争和改进的循环,在没有中心化控制的情况下随着时间的推移不断优化模型质量。
其核心目标是提高在 ARC-AGI-2 等衡量抽象问题解决能力的困难推理基准上的表现。为了实现这一目标,该系统整合了诸如联合嵌入预测架构(JEPA)和分层推理模型等方法,使模型能够构建内部表示、规划解决方案并适应新任务。其产出不是一个单一的固定模型,而是一个不断进化的去中心化 AI 系统。随着时间的推移,这些模型旨在通过网络 API 进行访问,支持语义搜索、复杂分析和通用推理等应用,同时保持开放、持续更新和集体开发。[1] [3]
历史
Hone(前身为 OpenKaito)起源于 Bittensor 生态系统中的 Subnet-5,最初专注于去中心化搜索和文本嵌入模型。2025年5月1日,该子网的所有权从其原始创建者转移到了 Latent Holdings,标志着方向和范围的转变。转移后,与 Manifold Labs 合作推出了新的发展战略。该子网不再主要关注搜索和嵌入,而是重新定位为使用分层 AI 架构构建通用推理系统。这一转型反映了从信息检索向更高级 AI 能力迈进的更广泛趋势。
2025年8月7日,Subnet-5 正式更名为 Hone,反映了其更新的技术重点和研究方向。从那时起,该项目以推理模型的去中心化训练为中心,在 Bittensor 框架内整合了世界模型学习和迭代推理等方法。Hone 的开发由 Manifold Labs 和 Latent Holdings 共同领导。Manifold 贡献了构建和运营 Bittensor 子网及相关基础设施的经验,而 Latent 则提供了专注于开源 AI 开发的战略方向。两家机构共同将 Hone 确立为一个去中心化的研究和基础设施项目,旨在推进通用 AI 系统。自重新发布以来,Hone 已从一个专门的、专注于嵌入的子网演变成一个更广泛的推理模型分布式训练和评估平台。[1] [2]
架构
世界模型学习
世界模型学习模块专注于自监督预测学习,借鉴了联合嵌入预测架构 (JEPA) 及其分层扩展。核心目标是通过预测缺失或掩蔽的信息来训练模型理解数据结构,而不是依赖标签监督。在实践中,模型会接触到部分输入——如不完整的模式、序列或结构化数据——并且必须推断出缺失部分的潜在表示。这鼓励系统学习变量之间的关系、因果结构和上下文,形成一种通常被称为“世界模型”的压缩内部表示。
一个关键方面是分层表示学习。模型不是学习单一的扁平嵌入空间,而是同时开发多个抽象层次——例如,底层特征(模式、标记)和高层概念(规则、关系)。这些层次允许系统更有效地跨领域泛化,因为它可以使用抽象知识,而不是死记硬背表层相关性。该模块作为系统的基础:它为模型提供了广泛的、可迁移的知识和上下文理解,这对于下游推理任务是必不可少的。如果没有这一步,推理模块往往会在浅层或脆弱的表示上运行。[1]
分层推理
分层推理模块建立在已学习的表示之上,并引入了受分层推理架构启发的显式多步推理过程。模型不是在单次前向传递中生成输出,而是结构化为两个相互作用的组件,这些组件在多次迭代中运行。高层组件充当规划者。它根据输入和当前的推理状态生成抽象策略、假设或部分解决方案。底层组件充当执行者,接收该规划并执行具体步骤——如填充细节、测试变换或构建中间输出。
这些组件在循环回路中交互。在每次迭代后,执行者的输出会反馈给规划者,规划者评估进度并决定是优化策略、调整假设还是终止过程。这创造了一个动态推理循环,模型在此过程中逐步改进其解决方案。这种设计使系统能够处理需要分解、回溯和迭代优化的任务——这些能力在标准的基于 Transformer 的模型中受到限制。它还实现了跨不同时间尺度的推理:较慢的高层规划指导较快的、注重细节的执行。分层结构还提高了计算效率。系统不是通过扩展单个大型模型来一次性处理所有推理,而是在多次迭代中重复使用较小的组件,在不按比例增加模型大小的情况下实现更深层次的推理。[1]
发现错误了吗?

平均评级
暂无评分
您的体验如何?
给这个维基一个快速评分让我们知道!
编辑者
2026年4月27日。02:46 UTC
编辑摘要:
Removed Hone overview content, capitalized Organizations title, normalized wallet ID case