0% read
Last updated:
NOVA
NOVA is a decentralized artificial intelligence network for early-stage drug discovery operating as Subnet 68 on the Bittensor ecosystem and developed by Metanova Labs. The project coordinates distributed participants to generate and evaluate synthesizable chemical compounds against biological targets using deterministic machine learning oracles, recording results on-chain for transparency and reproducibility. [1] [2]
Overview
NOVA is a decentralized AI network for drug discovery built as Subnet 68 on the Bittensor ecosystem and developed by Metanova Labs. It functions as a distributed platform for screening and optimizing potential drug compounds, reframing early-stage pharmaceutical research as a large-scale computational problem. The system coordinates global participants who contribute models and compute power to explore vast chemical spaces, searching for molecules likely to interact effectively with specific biological targets. This process is structured as a competitive and iterative workflow: some participants generate candidate molecules, while others evaluate their properties, enabling parallel exploration of large compound libraries.
At its core, NOVA’s build is a decentralized screening and optimization engine. It uses machine learning models to predict how molecules will bind to target proteins and avoid undesirable interactions with non-targets. These predictions are continuously refined through repeated evaluation cycles, allowing the network to identify candidates with stronger binding affinity and lower risk of side effects. The platform integrates multiple stages of early drug discovery, including virtual screening, model fine-tuning, and validation workflows. By distributing these tasks across a network and aligning incentives with performance, NOVA aims to accelerate the identification of viable drug candidates while reducing the time and cost typically associated with traditional pharmaceutical research. [1] [2]
Features
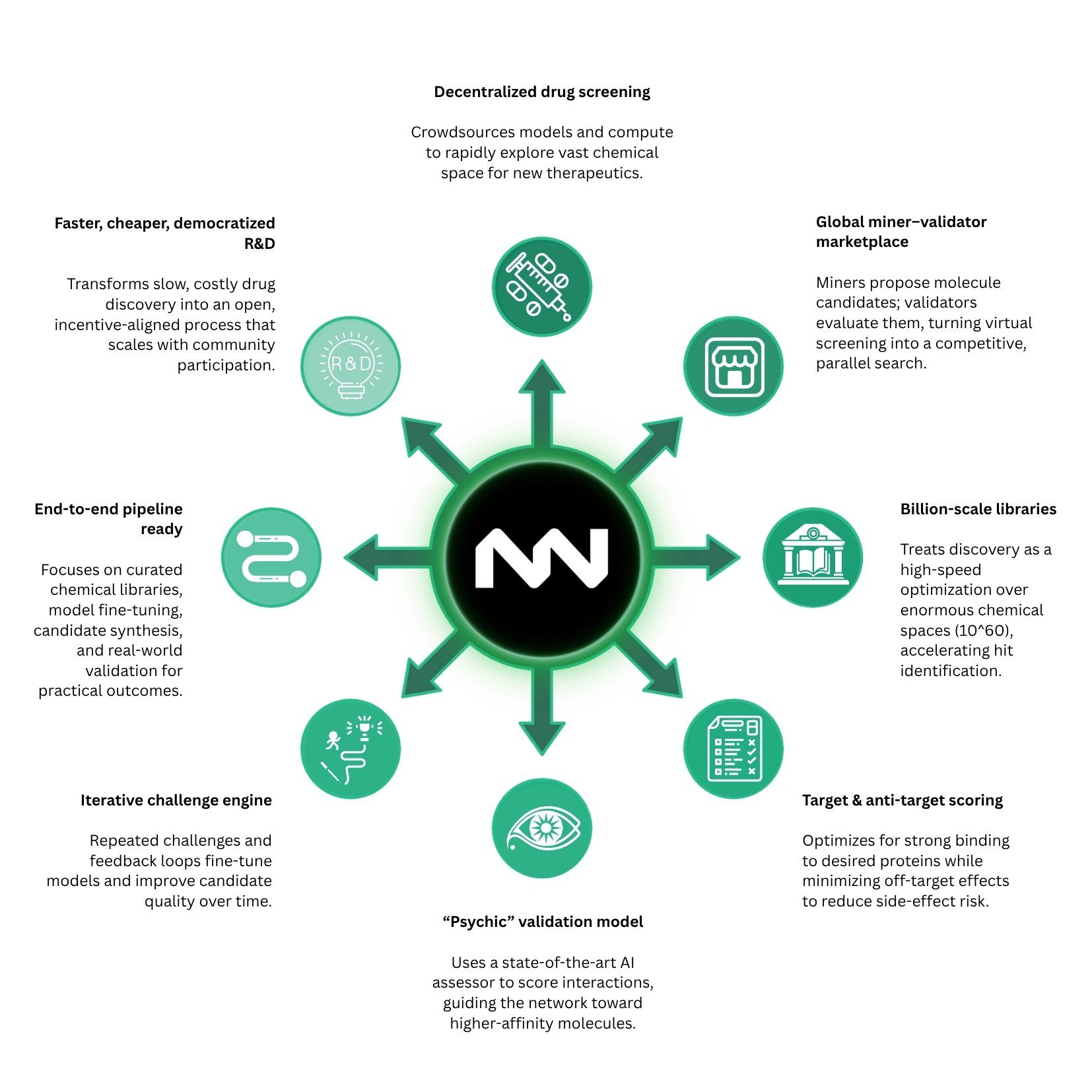
Decentralized R&D
NOVA enables open participation in drug discovery, allowing anyone to contribute as a miner or validator without institutional barriers. This creates a globally distributed network for early-stage pharmaceutical research where computation, model development, and evaluation are crowdsourced. All results, including molecule scores and top candidates, are recorded transparently on-chain, producing an open and continuously expanding dataset of evaluated compounds. [2]
Gamified Search
Drug discovery in NOVA is structured as a competitive optimization process where participants race to identify molecules with the highest predicted biological activity. The system runs in fast iterative cycles, with frequent feedback allowing miners to continuously refine and resubmit improved candidates. This transforms molecular screening into a real-time competitive environment where exploration of chemical space is directly rewarded and diverse strategies are incentivized. [2]
Objective Oracle
Evaluation is standardized through a deterministic machine learning model called PSICHIC, which predicts protein–ligand binding affinity. All validators use the same model to score molecules, ensuring that results are consistent, reproducible, and objectively comparable across the entire network. This removes subjective human judgment and establishes a single shared optimization function that all participants must maximize. [2]
Search Space & Dataset
The system operates over extremely large molecular datasets, including SAVI-2020, which contains roughly 1.75 billion synthesizable compounds. Unlike purely generative chemistry systems, these molecules are constrained to structures that can be produced using known chemical synthesis routes. This ensures that high-scoring candidates are not only computational predictions but also physically realizable, making outputs directly relevant to real-world drug development. [2]
DeSci & Web3 Integration
NOVA is built as part of a decentralized science framework that integrates open datasets, open-source models, and blockchain coordination. The full pipeline—from data and model evaluation to results—is transparent and reusable, allowing external researchers to inspect and build on the system. This shifts drug discovery away from closed pharmaceutical pipelines toward open, collaborative infrastructure. [2]
Architecture
NOVA’s architecture is designed as a competitive, oracle-driven optimization network where participants explore chemical space to identify molecules with high predicted biological activity. At a high level, the system combines protein–ligand binding prediction models, large-scale chemical search over synthesizable compound libraries, and a deterministic scoring oracle (PSICHIC) that standardizes evaluation across all participants. The goal is to transform drug discovery into a real-time, high-throughput optimization process across massive molecular search spaces. The architecture is composed of three core components:
- Miners are the exploration layer of the network. Each miner generates and refines candidate molecules by searching through an extremely large chemical space, including databases such as SAVI-2020, which contains roughly 1.75 billion synthesizable compounds. Miners use a mix of machine learning methods (such as QSAR models and deep neural networks) and heuristic strategies (such as substructure search, similarity matching, and active learning) to identify molecules likely to bind to a given protein target. Instead of brute-force search, miners iteratively improve their candidates using feedback from the system’s scoring mechanism. Each miner is constrained to maintain only one active molecule submission at a time, which is continuously updated whenever a better candidate is found. This creates a focused optimization process in which each participant effectively competes to refine a single best solution in real time.
- Validators form the evaluation and coordination layer. At the end of each block (approximately every 12 seconds), validators assess all submitted molecules using a shared deterministic scoring model. Their role is not to subjectively judge outputs, but to enforce consistent evaluation across the network and record performance outcomes on-chain. Validators compare all miner submissions and identify the highest-performing candidates for each evaluation cycle, which determines reward distribution.
- The key component enabling this consistency is the deterministic oracle, PSICHIC, a pretrained protein–ligand binding affinity model. PSICHIC takes protein sequences (or structures) and molecular representations (e.g., SMILES strings) as inputs and outputs a numerical binding affinity score. Because the model is fixed and deterministic, every validator produces identical scores for the same inputs, ensuring that evaluation is objective, reproducible, and transparent across the entire network. In effect, PSICHIC functions as the scoring function that defines the optimization target for all participants. [2]
Operation Modes
NOVA Compound
In Compound mode, miners submit sets of molecules per epoch for a specified target. Validators rescore each molecule using a composite procedure identified as Boltz-2, which combines predicted target affinity with entropy
- or novelty-based bonuses to encourage chemical diversity. Duplicate detection invalidates later occurrences of molecules previously submitted within the same target-week, and intra-submission duplicates or molecules failing property requisites (such as minimum heavy atoms or rotatable-bond thresholds) can disqualify submissions. Ranking is typically winner-take-all per challenge, with ties broken by earliest valid submission. This mode operationalizes a broad search under reproducible constraints while discouraging trivial repetition and promoting time-sensitive exploration of under-sampled regions of chemical space. Exact numeric weights, entropy formulas, and property thresholds vary by challenge and are not comprehensively enumerated in the public summaries, reflecting a protocol-level parameterization that may change over time. [1]
NOVA Blueprint
Blueprint mode evaluates generalizable search strategies rather than one-off molecule lists. Miners submit code that runs inside a standardized sandbox for a fixed runtime budget—reported as approximately 30 minutes on an NVIDIA RTX 4090 GPU. The code must output 100 molecules that are then rescored against a randomized set of target and anti-target proteins using the deterministic PSICHIC oracle. Ranking is based on the mean difference between predicted affinity for the target and anti-target panel, with intra-submission duplicates or failures of property requisites disqualifying results. The chemical space, reaction templates, and the target/anti-target set are randomized and undisclosed during submission windows, reinforcing the requirement that algorithms be robust and general rather than overfit to a specific known target. This mode also applies diversity thresholds and novelty enforcement to reduce degenerate solutions and encourage broader exploration. [1]
Scoring
Evaluation is standardized via deterministic oracles so that all validators produce identical scores for identical inputs. PSICHIC is presented as the primary protein–ligand affinity model, taking in protein sequence or structural information and molecular representations such as SMILES to output a numeric score. In Compound mode, an additional composite rescoring process known as Boltz-2 incorporates novelty/entropy to reward chemical diversity and discourage narrow exploitation; in Blueprint mode, ranking uses the average difference between target and anti-target predictions across a set of 100 molecules. The network enforces several fairness and anti-abuse mechanisms, including:
- Duplicate invalidation within a target-week, where earlier submissions prevail.
- Intra-submission uniqueness requirements; duplicates or property failures can disqualify a submission.
- Chemical property filters per challenge (e.g., heavy atom count, rotatable bonds).
- Entropy/novelty bonuses and diversity thresholds to deter trivial repeats and mode collapse.
Scoring and ranking proceed at block cadence, described as roughly 12 seconds per evaluation cycle, producing a rapidly updating leaderboard and per-block reward allocation. Rounds often span hundreds of blocks, allowing miners to iteratively refine and resubmit improved candidates. Certain descriptions indicate a single active-molecule constraint per miner in specific modes, while Compound mode allows batch submissions per epoch; this difference is noted as a protocol evolution or documentation inconsistency that should be clarified in the latest technical specification. [2] [1]
See something wrong?
Average Rating
No ratings yet, be the first to rate!
How was your experience?
Give this wiki a quick rating to let us know!
Edited By
On April 27, 2026. 02:56 UTC
Edit summary:
Updated multiple IDs and capitalized Dapps title