0% read
最后更新:
NOVA
NOVA 是一个用于早期药物研发的去中心化人工智能网络,作为第 68 号子网运行于 Bittensor 生态系统,并由 Metanova Labs 开发。该项目协调分布式参与者,利用确定性机器学习预言机,针对生物靶点生成并评估可合成的化学化合物,并将结果记录在链上,以确保透明度和可复现性。[1] [2]
概览
NOVA 是一个为药物研发而构建的去中心化 AI 网络,作为 Bittensor 生态系统中的第 68 号子网运行,由 Metanova Labs 开发。它作为一个分布式平台,用于筛选和优化潜在的药物化合物,将早期药物研究重新定义为一个大规模的计算问题。该系统协调全球参与者贡献模型和算力,以探索庞大的化学空间,寻找可能与特定生物靶点有效相互作用的分子。这一过程被结构化为一个竞争性的迭代工作流:部分参与者生成候选分子,而其他参与者评估其特性,从而实现对庞大化合物库的并行探索。
NOVA 的核心架构是一个去中心化的筛选和优化引擎。它使用机器学习模型来预测分子如何与靶点蛋白结合,并避免与非靶点产生不良相互作用。这些预测通过重复的评估周期不断完善,使网络能够识别出具有更强结合亲和力和更低副作用风险的候选药物。该平台整合了早期药物研发的多个阶段,包括虚拟筛选、模型微调和验证工作流。通过将这些任务分布在网络中并将激励措施与性能挂钩,NOVA 旨在加速可行候选药物的识别,同时降低传统制药研究中常见的成本和时间。[1] [2]
特性
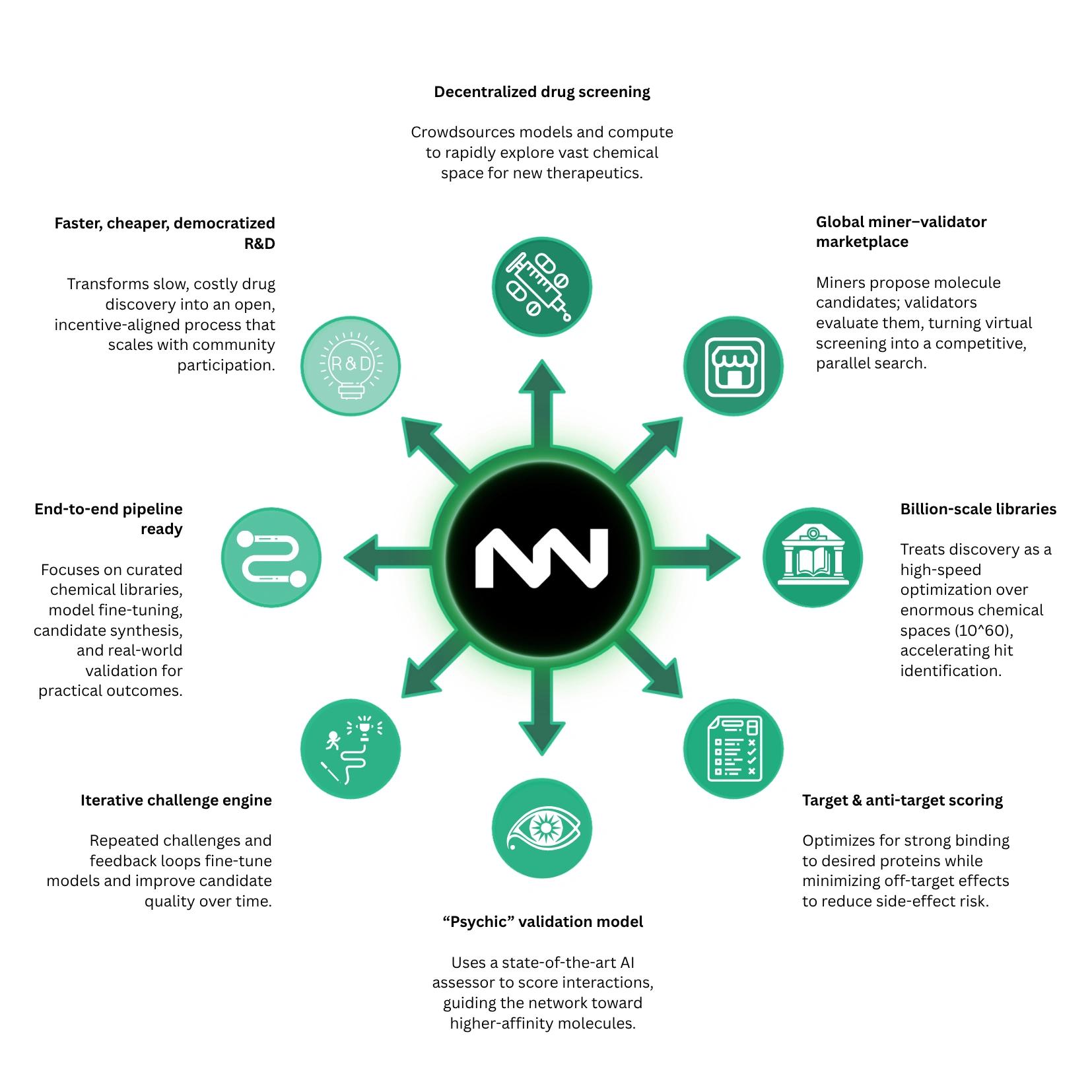
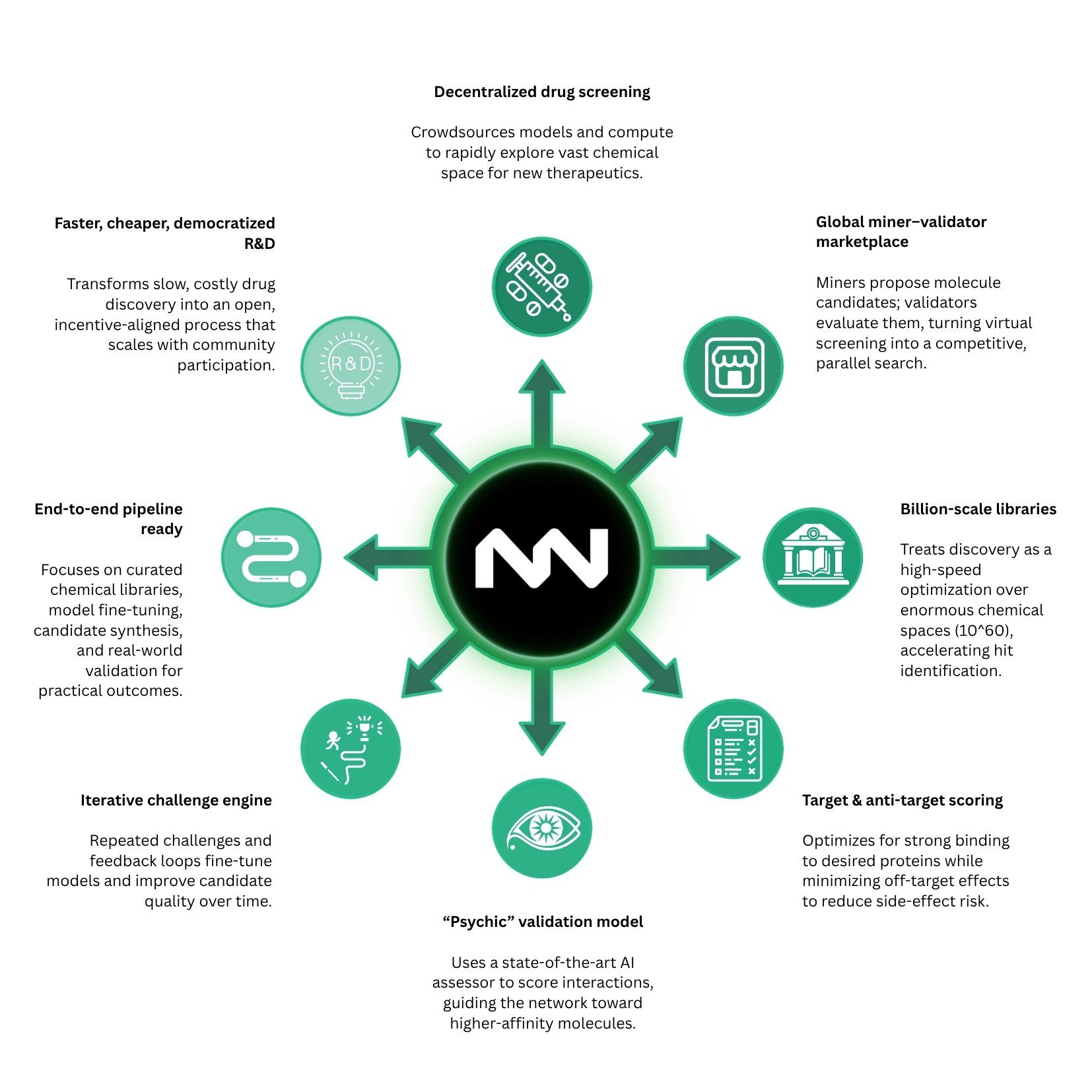
去中心化研发
NOVA 实现了药物研发的开放参与,允许任何人作为矿工或验证者做出贡献,不存在机构壁垒。这创建了一个全球分布式的早期药物研究网络,其中计算、模型开发和评估均通过众包完成。所有结果(包括分子评分和顶级候选药物)都透明地记录在链上,产生了一个开放且不断扩展的已评估化合物数据集。[2]
游戏化搜索
NOVA 中的药物研发被结构化为一个竞争性的优化过程,参与者竞相识别具有最高预测生物活性的分子。系统以快速迭代周期运行,频繁的反馈允许矿工不断完善并重新提交改进后的候选分子。这使分子筛选转变为一个实时的竞争环境,对化学空间的探索会直接获得奖励,并激励多样化的策略。[2]
客观预言机
评估通过名为 PSICHIC 的确定性机器学习模型进行标准化,该模型用于预测蛋白质-配体结合亲和力。所有验证者都使用相同的模型对分子进行评分,确保结果在整个网络中是一致的、可复现的且具有客观可比性。这消除了主观的人为判断,并建立了一个所有参与者必须最大化的单一共享优化函数。[2]
搜索空间与数据集
该系统在极大规模的分子数据集上运行,包括 SAVI-2020,其中包含约 17.5 亿种可合成化合物。与纯生成式化学系统不同,这些分子被限制在可以使用已知化学合成路径生产的结构内。这确保了高分候选者不仅是计算预测,而且在物理上是可实现的,使输出结果与现实世界的药物开发直接相关。[2]
DeSci 与 Web3 集成
NOVA 是作为去中心化科学(DeSci)框架的一部分构建的,该框架集成了开放数据集、开源模型和 区块链 协调。从数据和模型评估到结果的完整流程都是透明且可重复使用的,允许外部研究人员检查并在该系统上进行构建。这使药物研发从封闭的制药流程转向开放、协作的基础设施。[2]
架构
NOVA 的架构被设计为一个竞争性的、预言机驱动的优化网络,参与者在其中探索化学空间,以识别具有高预测生物活性的分子。从高层来看,该系统结合了蛋白质-配体结合预测模型、针对可合成化合物库的大规模化学搜索,以及一个在所有参与者之间标准化评估的确定性评分预言机 (PSICHIC)。其目标是在海量分子搜索空间中,将药物研发转化为实时的、高吞吐量的优化过程。该架构由三个核心组件组成:
- 矿工 (Miners) 是网络的探索层。每个矿工通过搜索极大的化学空间(包括包含约 17.5 亿种可合成化合物的 SAVI-2020 等数据库)来生成和完善候选分子。矿工结合使用机器学习方法(如 QSAR 模型和深度神经网络)和启发式策略(如子结构搜索、相似性匹配和主动学习)来识别可能与给定蛋白质靶点结合的分子。矿工不是进行暴力搜索,而是利用系统评分机制的反馈迭代改进其候选分子。每个矿工被限制一次只能维持一个活跃的分子提交,每当发现更好的候选者时就会持续更新。这创建了一个集中的优化过程,每个参与者实际上都在实时竞争以完善单一的最佳解决方案。
- 验证者 (Validators) 构成了评估和协调层。在每个区块结束时(大约每 12 秒),验证者使用共享的确定性评分模型评估所有提交的分子。他们的角色不是主观判断输出,而是在网络中执行一致的评估并将性能结果记录在链上。验证者比较所有矿工的提交,并识别每个评估周期中表现最好的候选者,从而决定奖励分配。
- 实现这种一致性的关键组件是确定性预言机 PSICHIC,这是一个预训练的蛋白质-配体结合亲和力模型。PSICHIC 将蛋白质序列(或结构)和分子表示(例如 SMILES 字符串)作为输入,并输出数值结合亲和力评分。由于该模型是固定且确定性的,每个验证者对相同的输入都会产生相同的评分,从而确保评估在整个网络中是客观、可复现且透明的。实际上,PSICHIC 充当了定义所有参与者优化目标的评分函数。[2]
运行模式
NOVA Compound (化合物模式)
在 Compound 模式下,矿工在每个 epoch 为指定靶点提交一组分子。验证者使用名为 Boltz-2 的复合程序对每个分子重新评分,该程序结合了预测的靶点亲和力与基于熵或新颖性的奖励,以鼓励化学多样性。重复检测会使在同一靶点周内先前提交过的分子后续出现失效,且提交内部的重复或未达到属性要求(如最小重原子数或可旋转键阈值)的分子可能会导致提交被取消资格。排名通常在每个挑战中采取“赢家通吃”制,平局则由最早的有效提交打破。此模式在可复现的约束下实现了广泛搜索,同时遏制了无意义的重复,并促进了对化学空间采样不足区域的时效性探索。具体的数值权重、熵公式和属性阈值随挑战而异,且未在公开摘要中全面列出,这反映了协议级别的参数化可能会随时间变化。[1]
NOVA Blueprint (蓝图模式)
Blueprint 模式评估的是通用的搜索策略,而非一次性的分子列表。矿工提交在标准化沙箱内运行的代码,并有固定的运行预算——据报道在 NVIDIA RTX 4090 GPU 上约为 30 分钟。代码必须输出 100 个分子,然后使用确定性 PSICHIC 预言机针对一组随机的靶点和非靶点蛋白进行重新评分。排名基于对靶点和非靶点组的预测亲和力平均差值,提交内重复或属性要求失败将取消结果资格。化学空间、反应模板以及靶点/非靶点集在提交窗口期间是随机且不公开的,这强化了对算法鲁棒性和通用性的要求,而非针对特定已知靶点的过拟合。此模式还应用了多样性阈值和新颖性强制执行,以减少退化解并鼓励更广泛的探索。[1]
评分
评估通过确定性预言机进行标准化,以便所有验证者对相同的输入产生相同的评分。PSICHIC 作为主要的蛋白质-配体亲和力模型,输入蛋白质序列或结构信息以及 SMILES 等分子表示,输出数值评分。在 Compound 模式下,名为 Boltz-2 的额外复合重评分过程结合了新颖性/熵,以奖励化学多样性并遏制狭隘的开发利用;在 Blueprint 模式下,排名使用 100 个分子集中靶点和非靶点预测之间的平均差值。网络执行多种公平和反滥用机制,包括:
- 靶点周内的重复失效,以较早的提交为准。
- 提交内唯一性要求;重复或属性失败可能导致提交被取消资格。
- 每个挑战的化学属性过滤器(例如,重原子计数、可旋转键)。
- 熵/新颖性奖励和多样性阈值,以阻止无意义的重复和模式崩溃。
评分和排名按区块节奏进行,描述为每个评估周期约 12 秒,产生快速更新的排行榜和按区块的奖励分配。轮次通常跨越数百个区块,允许矿工迭代完善并重新提交改进后的候选者。某些描述指出在特定模式下每个矿工有单一活跃分子的限制,而 Compound 模式允许每个 epoch 进行批量提交;这种差异被指出是协议演进或文档不一致,应在最新的技术规范中予以澄清。[2] [1]
发现错误了吗?
平均评级
暂无评分
您的体验如何?
给这个维基一个快速评分让我们知道!
编辑者
2026年4月27日。02:56 UTC
编辑摘要:
Updated multiple IDs and capitalized Dapps title