0% read
Openledger
Openledger
Openledger 是一个区块链网络,通过为开发和货币化专用人工智能模型提供去中心化基础设施来支持人工智能 (AI) 应用程序。它旨在创建一个经济框架,以促进人工智能驱动的生态系统内可验证的数据归属和加密经济激励。 [11]
概述
Openledger是一个区块链网络,通过为构建和货币化专用语言模型(SLM)提供去中心化基础设施来支持人工智能开发。它通过整合基于区块链的经济机制,解决了人工智能领域的挑战,例如访问专用数据、透明的归属和公平的补偿。Openledger使用分层架构:用于特定领域数据收集的数据网络、“归属证明”系统用于跟踪数据影响,以及基于OP Stack构建的、与EVM兼容的Layer 2网络,并使用EigenDA来实现数据可用性。生态系统内的所有操作,例如数据集上传、模型训练、奖励积分和治理参与,都在链上执行,以确保透明性和不变性。[13] 这种设置能够以低成本、可扩展的方式部署人工智能模型和应用程序,从而使贡献者、开发者和验证者能够在一个透明且可持续的人工智能生态系统中进行协作并获得奖励。[1] [2]
技术
数据网络
Openledger中的数据网络是去中心化的数据网络,旨在收集、验证和分发专门的数据集,用于训练特定领域的AI模型。这些网络作为结构化的、透明的存储库,贡献者可以在其中提供具有可验证归属的高质量数据。数据网络支持涉及所有者、贡献者和验证者的无需信任的系统,确保数据的准确性和完整性。用户可以创建新的数据网络或为现有的公共网络做出贡献。 [13] 专业数据对于提高AI模型的性能、可解释性和效率至关重要,这些模型是为特定领域量身定制的。数据网络在支持专业AI代理的同时,通过实现微调、可验证和可解释的模型开发,促进数据经济中可持续的、去中心化的参与。 [3] [12]
归属证明
OpenLedger的归属证明系统建立了一种密码学安全且透明的方法,用于将每个数据贡献与AI模型输出联系起来。这种机制确保了训练中使用的每个数据集都可以追溯到其来源,不可变地记录在链上,并评估其对模型行为的影响。它通过使贡献者能够获得与其数据价值成比例的奖励,同时通过惩罚系统阻止低质量或恶意输入,从而在AI开发中引入了问责制和信任。
归属过程始于贡献者提交带有元数据标记并存储在Datanets中的特定领域数据集。评估这些数据集对训练的特征级影响和贡献者的声誉,从而创建一个影响分数,确定他们的奖励份额。这些贡献在模型训练期间和之后被记录和验证,高影响数据导致更大的基于代币的激励。该系统通过区块链跟踪每个贡献(无论是数据、计算还是算法调整),确保所有参与者都以透明的方式得到认可和激励。 [13] 如果数据被标记为冗余、偏差或对抗性内容,贡献者将面临罚款,例如质押削减或减少未来的奖励。总而言之,归属证明支持一个无需信任且可验证的数据归属管道,激励高质量的参与,同时确保模型的完整性和透明度。 [4] [5]
RAG 归因
OpenLedger 的 RAG 归因系统集成了检索增强生成 (RAG) 与基于 区块链 的数据归因,以确保 AI 生成的输出可验证且奖励一致。在此框架中,来自 AI 模型的每个响应都由从 OpenLedger 的索引数据集中检索的数据支持,每个来源都归因于其原始贡献者。这种方法提高了模型输出的准确性和可靠性,并保持完整的数据来源和可追溯性,从而降低了错误信息的风险。
RAG 归因管道从用户提交查询开始,提示模型从 OpenLedger 的去中心化数据存储库中检索相关数据。每个检索到的信息都经过加密记录,确保其使用记录在链上。这些数据集的贡献者会根据其数据在响应中的使用频率和重要性获得微奖励。此外,该系统将透明的引用嵌入到模型输出中,使用户能够验证生成内容的来源。这种结构激励高质量的数据贡献,同时建立对 AI 驱动洞察的信任。 [6]
产品
模型工厂
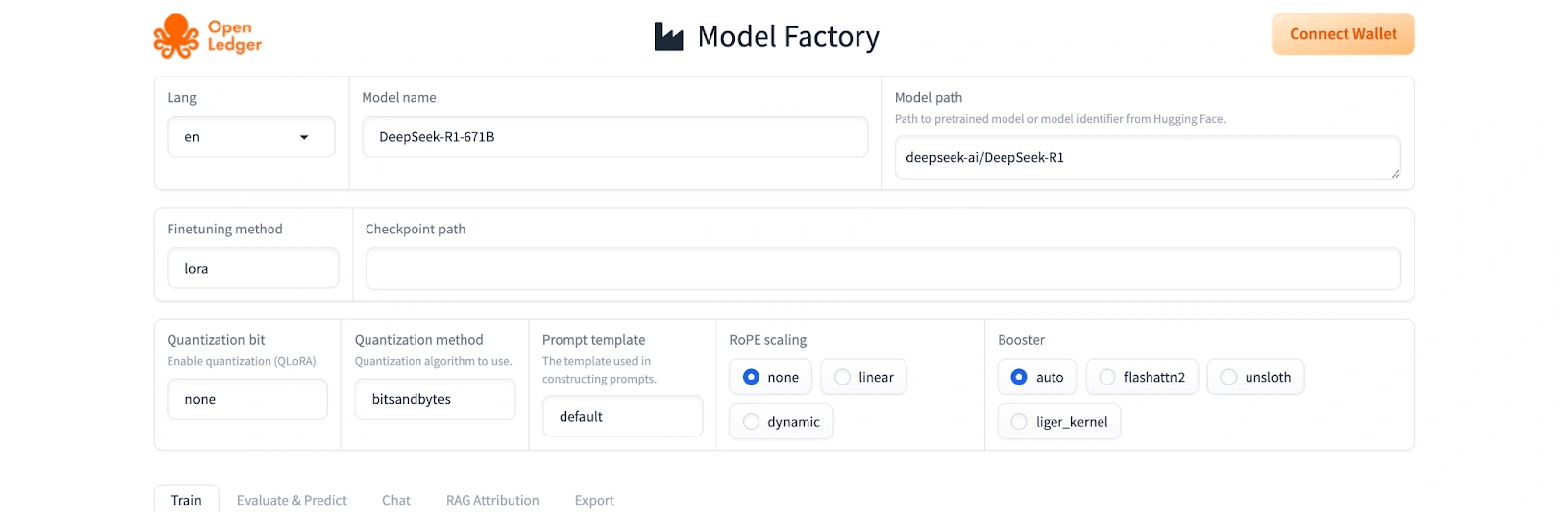
ModelFactory是OpenLedger的无代码平台,用于使用许可数据集安全地微调大型语言模型(LLM)。它用完全图形化的用户界面取代了传统的命令行工具和API,使技术和非技术用户都能微调LLaMA、Mistral和DeepSeek等模型。用户请求访问存储在OpenLedger存储库中的数据集,一旦获得批准,这些数据集将直接集成到ModelFactory工作流程中。模型选择、配置、训练和评估都通过直观的仪表板和LoRA和QLoRA等支持方法进行管理。
ModelFactory的一个关键特性是其安全的数据集访问控制,该控制保留了贡献者权限并确保负责任的数据使用。微调后的模型可以通过内置的聊天界面进行测试,从而实现实时交互。该平台还集成了RAG归因,将生成的输出与源引用配对,从而增强了透明度和数据来源。通过对模块化扩展、实时训练分析和端到端模型部署的支持,ModelFactory能够在分散的环境中实现可信赖、可扩展的AI模型开发。 [7] [8]
Open LoRA

Open LoRA 是一个可扩展的框架,可以在单个 GPU 上高效地服务数千个微调的 LoRA(低秩适应)模型。它通过动态适配器加载优化资源使用。它允许从 Hugging Face 或自定义文件系统即时访问 LoRA 适配器,从而减少内存开销,避免预加载所有模型。 Open LoRA 支持按需合并适配器以进行集成推理,从而实现灵活高效的模型切换,而无需部署单独的实例。
该框架通过张量并行、闪存注意力、分页注意力和量化等优化措施来提高推理性能,确保高吞吐量和低延迟。其可扩展性使得能够同时经济高效地部署许多微调模型,而令牌流和量化等功能进一步提高了推理速度和效率。 Open LoRA 特别适用于需要快速、资源高效地访问大量微调模型的应用程序。 [9]
用例
Openledger的基础设施支持围绕去中心化人工智能经济的各种应用。主要用例包括数据管理、模型训练、货币化推理和社区主导的治理。 [13]
数据管理和贡献
用户可以创建新的、专门的Datanet或贡献给现有的公共数据集。此过程旨在构建高质量、特定领域的数据存储库,用于训练人工智能模型。每一项贡献都会经过验证并记录在区块链上,贡献者会根据其数据的归属获得奖励,从而激励他们提供有价值的信息。 [13]
去中心化模型训练和微调
该平台提供使用来自数据网络的数据以分散方式训练和微调人工智能模型的工具。它支持先进的技术,允许在单个GPU上高效部署多个模型,从而提高性能并降低成本。所有对训练过程的贡献,包括数据、计算能力和算法调整,都会在链上进行跟踪,以确保所有参与者得到透明的认可和激励。 [13]
货币化的AI推理和归属
当Openledger上的AI模型用于生成输出(推理)时,系统会追踪使用了哪个模型以及它所训练的数据。这种归属过程允许平台将奖励分配给对模型开发做出贡献的个人和团队。这使得每一次AI交互,例如聊天回复或API调用,都成为生态系统贡献者的可盈利事件,从而在AI使用和补偿之间建立透明的链接。 [13]
去中心化治理
该平台的治理是通过混合链上系统进行管理的。原生OPEN代币的持有者可以参与指导协议的未来,对升级提案和其他生态系统决策进行投票。这确保了Openledger网络的开发和管理由其利益相关者社区指导。 [13]
Tokenomics
OPN 代币是 OpenLedger 生态系统的基础 utility 和 governance 资产,旨在支持可持续的去中心化 AI 经济。它具有多种功能,包括启用链上治理、支付 OpenLedger 的 Layer 2 网络上的 transaction fees,以及奖励数据贡献者、AI 开发者和 validators。代币持有者可以对生态系统决策进行投票,例如模型资金、AI agent 策略和国库分配。治理由使用 OpenZeppelin 的模块化 Governor 框架的 hybrid 链上系统提供支持,并提供委托治理选项以供更广泛的参与。 [13]
除了治理之外,OPN 还用作 gas 用于 L2 交易,减少对 ETH 的依赖,并允许针对 AI 工作负载优化的费用模型。它还充当奖励机制,激励措施与数据贡献和 AI 服务性能的质量和影响相关联。这会将每次 AI 交互转化为 across 生态系统中贡献者的可货币化事件。 [13] 此外,该代币支持 OpenLedger 和 Ethereum 之间的桥接,从而实现跨链功能。AI agent staking 的一个关键实用程序是,代理必须锁定 OPN 才能运行,性能不佳或恶意活动会导致削减。该 staking 系统强制执行质量标准并促进可靠的 AI 服务交付。总体而言,OPN 锚定了 OpenLedger 的经济和运营层,从而协调了 across AI agents、数据提供商和开发人员之间的激励措施。 [10]
合作伙伴关系
发现错误了吗?

平均评级
暂无评分
您的体验如何?
给这个维基一个快速评分让我们知道!
编辑者
2025年9月16日。17:28 UTC
编辑摘要:
feat: Add Use Cases and Tokenomics sections, restructure article



