0% read
Inflectiv
Inflectiv
Inflectiv is a data infrastructure platform designed to transform unstructured information into tokenized, structured datasets for use in artificial intelligence applications. The project aims to establish a marketplace where data contributors can monetize their knowledge and AI developers can access verified, high-quality data. [1] [2]

Overview
Inflectiv was developed to address the issue of "trapped knowledge," where valuable information is siloed in formats such as PDFs, standard operating procedures (SOPs), and academic research, rendering it inaccessible to large language models (LLMs) and AI agents. The project addresses challenges in the AI sector, where a lack of structured data often leads to unreliable outcomes and failed implementations. Inflectiv’s process involves uploading documents or expertise, converting them into structured data assets backed by its native token $INAI, and deploying them across workflows and applications. Users who contribute knowledge receive compensation for its utilization over time. [2] [5]
The platform is designed for a diverse user base, including AI developers who need clean, domain-specific data; academic institutions and researchers seeking to monetize their expertise; enterprises aiming to scale AI implementation using internal data; and Web3 projects that manage on-chain and off-chain information. The project has reported securing $100,000 in funding and states that over 500 datasets are available on its platform. The system is intended to be a "0-code" solution, enabling users to process data without needing programming skills. [1]
Products
Inflectiv's platform consists of several core products that create its data ecosystem. These tools facilitate the entire lifecycle of data transformation, from raw information to a monetizable asset. The primary offerings include a web application for data processing and a proof-of-concept application built on the Sui network.
The platform's product suite is broken down into three main components:
- Dataset Engine: A set of tools for data contributors to upload raw information from sources like documents and research papers. The engine helps structure this data into composable and queryable assets, known as knowledge graphs, preparing it for tokenization and licensing.
- Data Exchange (DDEX): A marketplace where contributors can create, tokenize, and list their structured datasets. It also allows backers to fund the launch of new datasets, with the goal of fostering a community-driven market for data assets.
- Developer Tools: A collection of APIs and SDKs that enable developers to integrate the platform's structured datasets into their applications, AI agents, and data pipelines. These tools are designed for compatibility with major AI frameworks and Web3 protocols. [1]
Ecosystem
The Inflectiv ecosystem is designed to connect data creators, curators, and consumers in a self-reinforcing cycle. This model, described by the project as a "flywheel," involves two primary user groups: Knowledge Creators and AI Builders. Knowledge Creators—such as researchers, academic institutions, enterprises, and Web3 projects—contribute their siloed data to the platform using the Dataset Engine. [2]
As the volume and quality of available datasets increase, the platform becomes more valuable to AI Builders, who are the consumers of the data. These developers and enterprises use the Developer Tools to access and integrate the structured data into their AI models and applications. The revenue generated from this usage is then used to reward the Knowledge Creators, which in turn incentivizes the contribution of more high-quality data, perpetuating the growth of the ecosystem. Backers and community members can also participate by funding, trading, and curating datasets on the Data Exchange. [1] [2]
Use Cases
- AI Development: Providing AI builders with access to clean, structured, and domain-specific data to train more accurate models and reduce the occurrence of AI hallucinations.
- Knowledge Monetization: Enabling researchers, academics, and institutions to tokenize and sell their expertise and research findings as structured data assets.
- Enterprise AI Scaling: Assisting businesses in leveraging their internal, siloed data, such as SOPs and reports, to scale AI applications without requiring extensive prompt engineering.
- Web3 Data Management: Offering Web3 projects and DAOs a framework for structuring and utilizing on-chain and off-chain data to generate market intelligence. [1]
Tokenomics
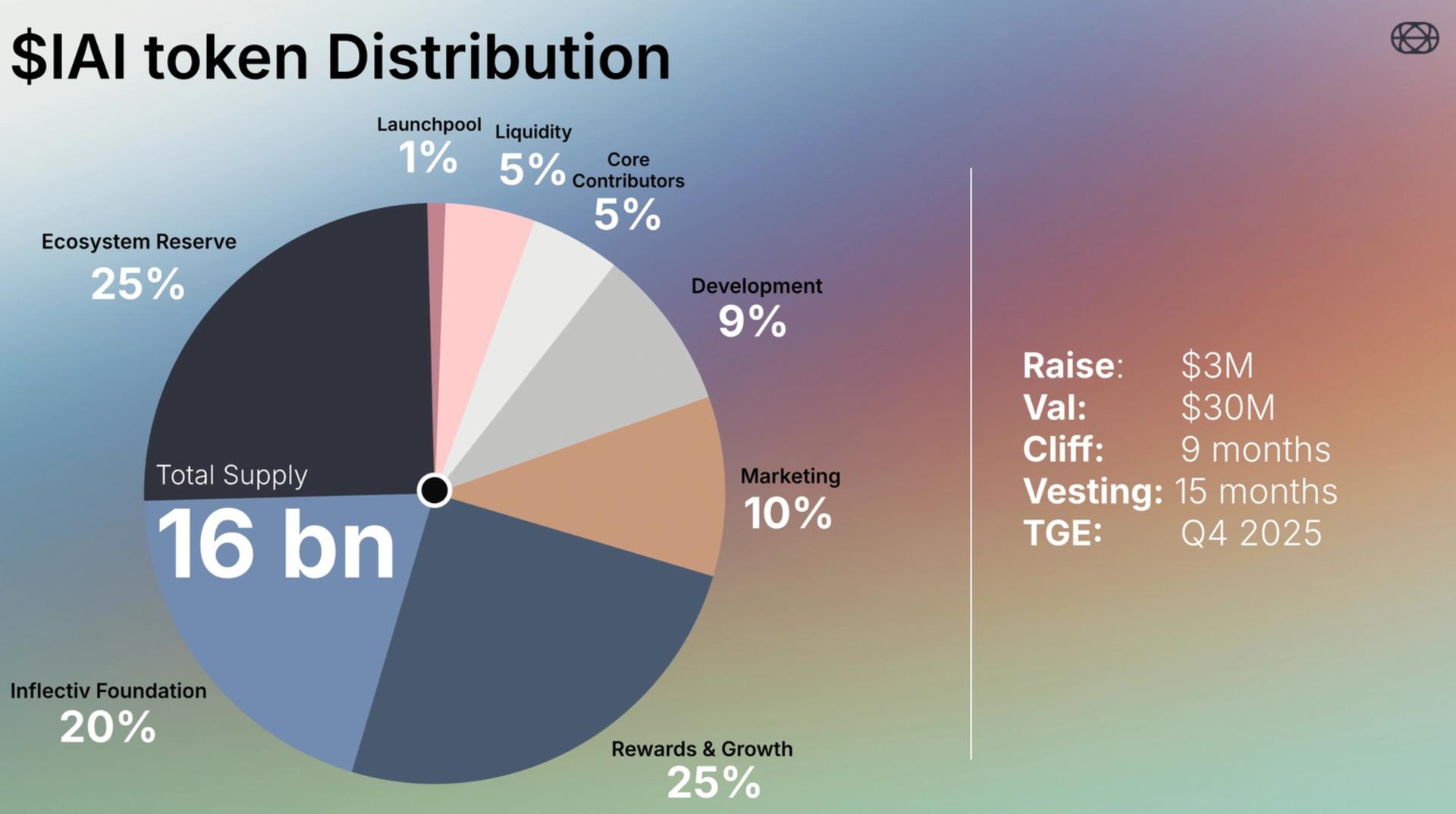
Inflectiv plans to introduce a native utility token for its ecosystem, designated as $INAI. The project has scheduled a Token Generation Event (TGE) for the fourth quarter of 2025. [2]
The total supply of $INAI tokens is set at 16 billion. Distribution is structured as follows:
- Rewards and Growth: 25%
- Ecosystem Reserve: 25%
- Inflectiv Foundation: 20%
- Marketing: 10%
- Development: 9%
- Core Contributors: 5%
- Liquidity: 5%
- Launchpool: 1%
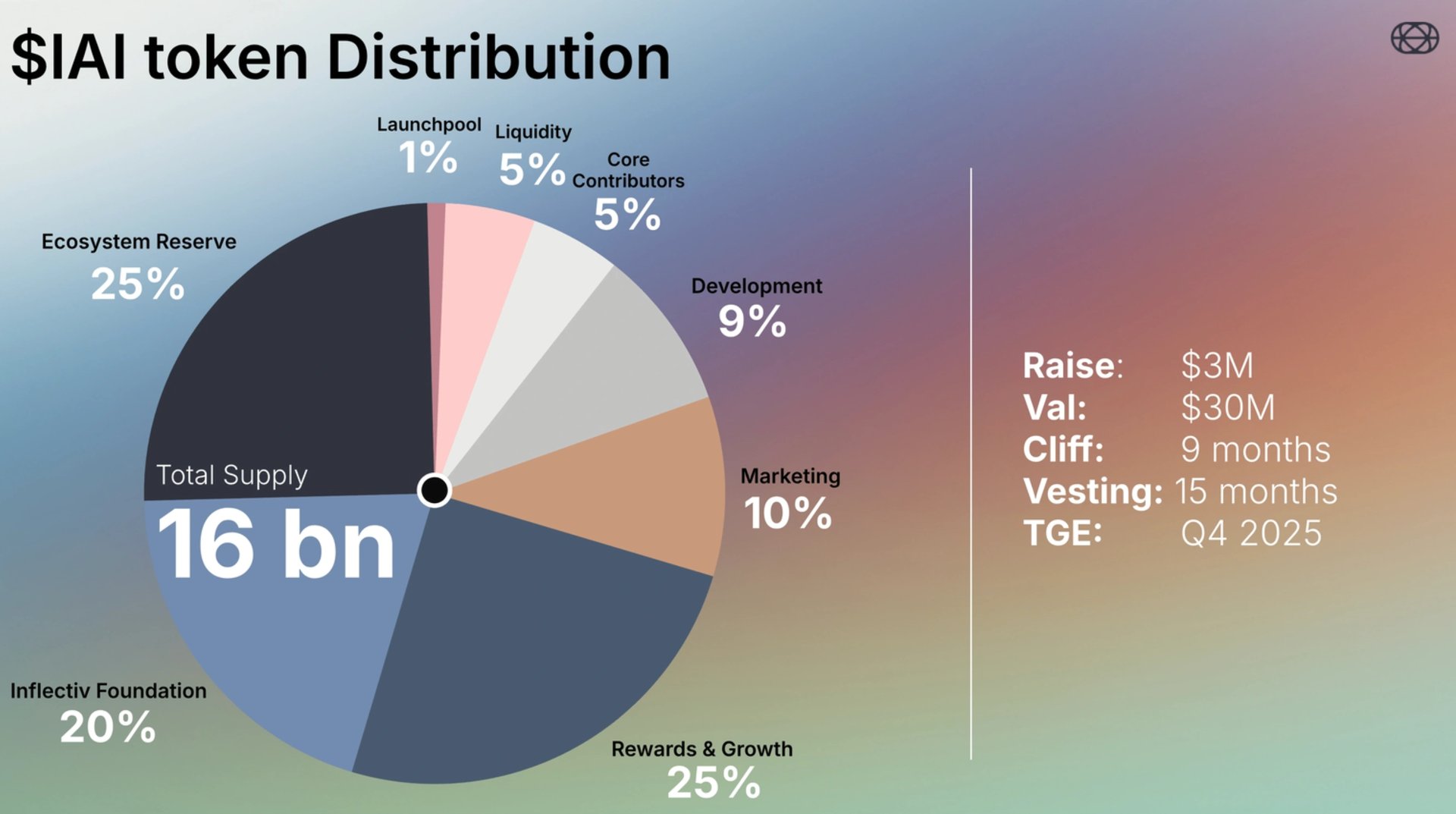
In terms of economics, Inflectiv reported a raise of $3 million at a valuation of $30 million. Token release conditions include a 9-month cliff, followed by a 15-month vesting period, with the Token Generation Event (TGE) scheduled for Q4 2025. [3]
Token Utilities
- Monetization and Access: The token is used as the medium of exchange for developers and enterprises to pay for access to datasets. It is also used to monetize the datasets created and uploaded by contributors.
- Creator Rewards: $INAI is distributed to dataset creators, curators, and validators as compensation for their contributions to the platform.
- Traceability: It functions as a mechanism for on-chain traceability, tracking the provenance and usage of data assets within the ecosystem.
- Staking: The token will be used for staking requirements within the protocol.
- Burn Mechanism: The tokenomics model is expected to include a burn mechanism to help manage the token supply. [2]
Partnerships
Inflectiv has announced several integrations and partnerships with organizations in the Web3 and cloud computing sectors to build its platform and ecosystem. The project has also stated it is running pilots with undisclosed universities, DAOs, and enterprise teams and has secured over 15 partnerships within the Web3 space.
See something wrong?

Average Rating
No ratings yet, be the first to rate!
How was your experience?
Give this wiki a quick rating to let us know!
Edited By
On September 8, 2025. 03:43 UTC
Edit summary:
docs: Update IPFS content identifier (CID) to point to the latest resource version.